How to extract text using RutaText operator
Preconditions
With the Java Operator RutaText, available from https://github.com/IBMStreams/streamsx.nlp, you can extract data from incoming text. As precondition, you need IBM Streams release 3.2 or newer and previously developed UIMA Ruta rules that are packed into a PEAR.
There are many ways to develop PEAR files. Among them are IBM Watson Content Analytics (ICA) Studio and UIMA Ruta workbench. One example how to create a UIMA Ruta PEAR is part of the toolkit documentation.
Text extraction is one possible step in the natural language processing pipe. Previous steps might be lemma transformation and removal of stop words. There are separate operators for those steps available in the IBM Streams Natural Language Processing (NLP) Toolkit. This article just concentrates on the RutaText operator.
Glossary
UIMA - Unstructured Information Management Architecture, an Apache open source project.
Apache UIMA implements an extensible framework for analysis of unstructured content such as text, audio and video. Annotator components - also known as Analysis Engines (AE) - are the ones that do the extraction work. The framework also covers development tools and a framework to chain multiple components.
Ruta - is a rule based text annotation language.
Apache UIMA Ruta delivers the analysis engine to interpret the rule language and a workbench (Eclipse plugin) for rules development.
CAS - Common Analysis System, an object-oriented data structure to carry the data for analysis together with types and extracts.
UIMA follows the policy to hold all data as CAS. Using UIMA components means transforming data into CAS first. For output of CAS the XMI format is used.
PEAR - Processing Engine ARchive.
The UIMA framework supports to package an Analysis Engine into a PEAR file. Other components can use it from that PEAR.
XMI - XML Metadata Interchange.
A standard for exchanging metadata information. UIMA delivers tools to display XMI content.
Overview
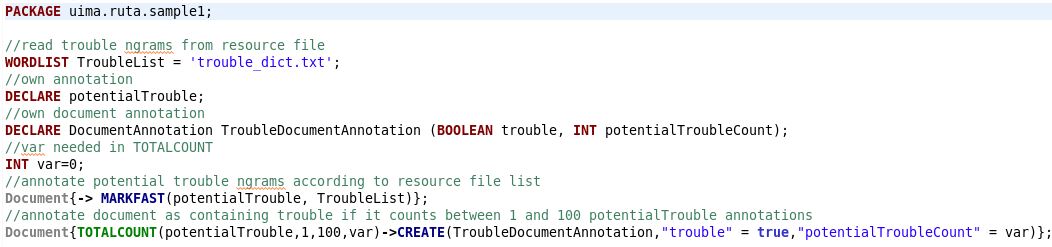
In this example, a PEAR file contains UIMA Ruta rules that annotate groups of words in a document that might mean “trouble” according to a dictionary. Additionally, it calculates a trouble count per document and adds it as document annotation.
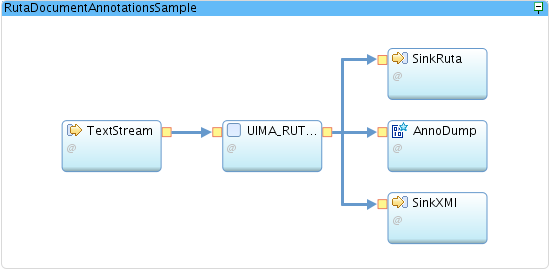
The RutaText operator applies those rules to incoming text documents. The input file is read line by line. Each line of the input file represents one document to analyze and is processed as input tuple in the RutaText operator, which output is connected into three different directions:
- To the console.
- As text file.
- As XMI file. This file is the serialized UIMA CAS format output. It is useful as input for further UIMA operators like
UimaCasorRutaCasthat might deliver further extracts.
The Input
TextStream is a FileSource operator that forwards the stream attribute text.
In the sample text file with line breaks you see the following text:
My phone freezes when using this app.
super quality
very angry about wifi not connecting and no internet
The UIMA Ruta Rules
The Ruta PEAR contains a dictionary, descriptors, and rules. Potential trouble entries are part of dictionary TroubleList. The rules annotate matches from the input text to the dictionary as potentialTrouble. They summarize per line the trouble matches. The references section lists a link to a description how to create a UIMA Ruta PEAR. This description is part of the IBM Streams NLP Toolkit documentation. The following code snippet shows the sample Ruta rules.
The RutaText operator using the Ruta Rules
The RutaText operator installs the PEAR at runtime and interprets the rules running the UIMA Ruta Analysis Engine. The only required parameter is pearFile. If the input contains multiple attributes, you need to give the attribute that is subject to RutaText analysis in the inputDoc parameter. As UIMA Ruta rules generate a huge amount of implicit annotations by design, optional you can filter that ones you are interested in - with the outputTypes parameter. The parameter outputAttributes defines names for the non-XMI output attributes. The parameter casOut causes the RutaText operator to serialize CAS to XMI format as output. The value of parameter casOut is used as name for the XMI output. It automatically adds the extension .xmi to this name. If you skip the casOut parameter, you would not get this output format created.
The AutoSpan type covers attributes of both types the Ruta rules from the sample PEAR annotate. Depending on the typeDescription value only parts of the attributes are valid. For the type uima.ruta.sample1.Main.TroubleDocumentAnnotation only the attributes trouble and potentialTroubleCount are valid. If the type value is uima.ruta.sample1.Main.potentialTrouble, then the attributes text, begin and end are used.

The Output
The RutaText operator produces output in two attributes: annotations and xmi. Every attribute contains the full extract result in a different form for different subsequent usage. The sample demonstrates usage of both. In practice, if you only need one, you can skip the other for better performance.
Attributes that are present in input and output stream with the same name and type are automatically forwarded. In the sample that is attribute text.
The custom operator AnnoDump produces the console output that is shown based on the annotations output attribute. It contains annotations that are extracted from the input text. Lines 1 and 3 contained potential trouble. The extracted trouble text annotations follow together with their begin and end positions relative to the affected line. For line 2, no potential trouble is found.
[1] trouble=true, potentialTroubleCount=1 [text=phone freezes, begin=3, end=16]
[3] trouble=true, potentialTroubleCount=2 [text=wifi not connecting, begin=17, end=36][text=no internet, begin=41, end=52]
The FileSink operator SinkRuta produces file out.txt in a comma-separated value (CSV) format from the text and annotations attributes.
The FileSink operator SinkXMI produces file out.xmi in XMI format from the xmi output attribute. UIMA brings separate tools for XMI format display - offline and integrated with Eclipse via UIMA plugin. The following figure shows how the out.xmi display looks like in the UIMA Eclipse plugin.

Summary
With the com.ibm.streamsx.nlp::RutaText operator you get an alternative to the IBM Streams AQL com.ibm.streams.text.analytics::TextExtract operator. Instead of AQL rules it uses UIMA Ruta rules packaged in a PEAR. It can produce various output formats. The same format as AQL com.ibm.streams.text.analytics::TextExtract (if needed for replacement) as well as standardized XMI.
References
-
How to create a Ruta PEAR? https://github.com/IBMStreams/streamsx.nlp/blob/develop/com.ibm.streamsx.nlp/doc/UIMA_workbench.pdf
-
Apache UIMA Ruta Workbench https://uima.apache.org/d/ruta-current/tools.ruta.book.html#ugr.tools.ruta.workbench
-
Apache UIMA Ruta (Rule based text annotation) https://uima.apache.org/ruta.html
-
IBM Watson Content Analytics (ICA) Studio https://www.ibm.com/support/knowledgecenter/en/SS5RWK_3.5.0/com.ibm.discovery.es.in.doc/iiysicasrun.htm