Improving application throughput when consuming from Kafka
This article demonstrates a technique to improve the overall throughput of a Streams application that is consuming messages from Kafka. It will also show how you can scale up a Streams application without having to recompile it.
An interesting feature provided by Kafka is the ability to provide load balancing when consuming messages. An application can be configured with multiple consumer instances, with each consumer receiving a portion (or share) of the messages on the topic. This functionality enables applications to scale out as the amount of data being written to the topic increases. It also provides the added benefit of high availability: if one of the consumer instances crashes, the messages can be rerouted to the other consumers.
Kafka Topics, Partitions and Groups
Before diving into how to configure Kafka load balancing in a Streams application, some important Kafka concepts need to be understood. Specifically, the concepts of a topic, partition and consumer group.
Kafka Topics and Partitions
In Kafka, a topic is a category or feed to which records are written to. A topic is similar (albeit slightly different) to the concept of queues used by other messaging systems.
Each Kafka topic can contain one or more partitions. A partition is an ordered sequence of records that is continually appended to. Whenever a record is written to a topic, it is routed to a partition within the topic. The following image from the Apache Kafka documentation shows what the anatomy of a topic looks like:
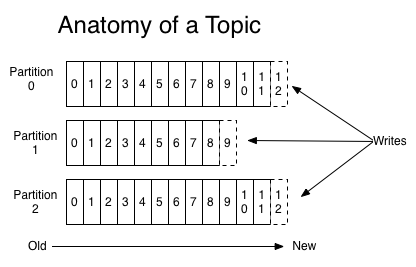
Whenever a consumer connects, it is assigned to one or more partitions. The messages received by the consumer will only come from the partitions it is assigned to.
Load balancing is achieved by assigning different partitions to different consumers. For example, if a topic contains 5 partitions, then you can have 5 consumers connect with each receiving messages from a different partition. While this assignment can certainly be managed manually, a better approach is to use Kafka groups so that in the event a consumer crashes, the partitions it was assigned to can be automatically redistributed to the other consumers.
Kafka Consumer Groups
As mentioned previously, load balancing is achieved by assigning topic partitions to different consumers. In order to achieve automatic assignment of partitions to consumers, each consumer instance can label itself as being part of a consumer group. Multiple consumer instances can be part of the same group, or to put it another way, a group can contain one or more consumers. When a consumer subscribes to a topic, the group that it is part of will automatically assign topic partitions to that consumer. If multiple consumers in the same group subscribe to the same topic, the group will assign different partitions to each consumer. This ensures that each group of consumers will only receive and process a message once.
The following image from the Apache Kafka documentation demonstrates what this looks like:
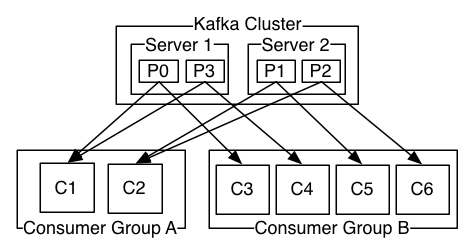
For more information on how topics, partitions and groups work, please refer to the Apache Kafka documentation.
Configuring Streams Application to use Kafka’s Group Functionality
Now that we understand that the goal to achieving automatic load balancing in Apache Kafka is to assign multiple consumers to the same group, we can look at how to accomplish this within the context of a Streams application. There are 2 main parts to configuring loading balancing with the KafkaConsumer operator in a Streams application:
- Create multiple instances of the KafkaConsumer operator
- Assign each instance to the same group
For the first item, the brute force approach is to simply add multiple KafkaConsumer operators to your application. With this approach, the developer will need to ensure that each operator is connecting to the correct topic and is using the same set of properties. A better approach is to use Streams’ User-Defined Parallelism (UDP) feature. In a nutshell, UDP allows a developer to create multiple copies of the same operator by adding the @parallel annotation to the operator. With this method, the develop only needs to configure the KafkaConsumer operator once. Each instance created by the UDP feature will contain the same set of configurations. The following SPL code snippet comes from the KafkaConsumer Load Balancing Sample found in the streamsx.kafka GitHub repository.
namespace com.ibm.streamsx.kafka.sample;
use com.ibm.streamsx.kafka::KafkaConsumer;
use com.ibm.streamsx.kafka::KafkaProducer;
public composite KafkaConsumerLoadSample {
type
Message = rstring key, rstring message;
graph
@parallel(width = 3)
stream<Message> KafkaMessages = KafkaConsumer() {
param
topic: "test";
propertiesFile: "etc/consumer.properties";
}
() as PrintOut = Custom(KafkaMessages) {
logic
onTuple KafkaMessages: {
println(KafkaMessages);
}
}
// ... remainder of application can be viewed on GitHub ...
}
The above code snippet shows that the @parallel annotation is applied to the KafkaConsumer operator and that the width property is set to a value of 3. This means that 3 instances of the KafkaConsumer operator will be created when the application is run.
The second item states that each instance needs to be assigned to the same group. This is achieved by setting the group.id Kafka configuration property. Kafka configuration properties can be specified either in an application configuration or in a properties file. In the code snippet above, the KafkaConsumer is reading the properties from the file etc/consumer.properties. This file contains the following:
bootstrap.servers=
group.id=load_balance_sample
The etc/consumer.properties file contains the line group.id=load_balance_sample. Since each instance of the KafkaConsumer operator is loading the same properties file, then each instance will be added to the group named “load_balance_sample”. When the application is run, Kafka will assign each of the instances in this group to a different partition (or set of partitions).
After setting the bootstrap.servers property to your servers, for example localhost:9092 in etc/consumer.properties and etc/producer.properties, the configuration is complete and the application can be launched. Here is what the running application looks like when submitted to an instance:
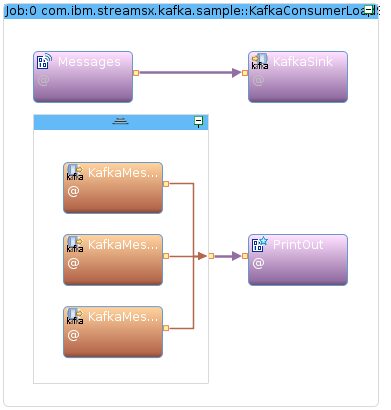
The above image shows three instances of the KafkaConsumer operator. This due to the fact that the @parallel annotation was specified with a width of 3. Increasing the width value will result in more instances of the KafkaConsumer operator.
Setting the Number of Consumers at Submission-Time
One of the neat features of SPL annotations is that they are capable of accepting submission-time values. This means that the number of KafkaConsumers used for load balancing can be determined at submission-time, rather than hard-coded into the application. This frees the developer from having to know beforehand how many consumers will be required.
Here is the previous code snippet again, only instead of hard-coding the width of the parallel region, it is determined at submission-time.
namespace com.ibm.streamsx.kafka.sample;
use com.ibm.streamsx.kafka::KafkaConsumer;
use com.ibm.streamsx.kafka::KafkaProducer;
public composite KafkaConsumerLoadSample {
type
Message = rstring key, rstring message;
graph
@parallel(width = (int32)getSubmissionTimeValue("num.kafka.consumers")) // <<== HERE
stream<Message> KafkaMessages = KafkaConsumer() {
param
topic: "test";
propertiesFile: "etc/consumer.properties";
}
() as PrintOut = Custom(KafkaMessages) {
logic
onTuple KafkaMessages: {
println(KafkaMessages);
}
}
// ... remainder of application can be viewed on GitHub ...
}
Another advantage of this approach is that you could add more consumers without having to recompile the application if you found that the initial number of consumers was insufficient. All you would need to do is resubmit the application and specify a different number of consumers.
Conclusion
This article demonstrated how a Streams application can increase the throughput when consuming from Kafka. This is accomplished by using Kafka’s Group Management functionality combined with Streams’ User-Defined Parallel regions. By running multiple instances of the KafkaConsumer operator that are all part of the same group, Kafka will automatically distribute the load across all of the consumers in the group. Lastly, this article talks about how the number of KafkaConsumers can be specified at submission-time, rather than hard-coded into the application.