-
- Type Parameters:
T- Tuple type, any instance ofTat runtime must be serializable.
- All Superinterfaces:
- Placeable<TStream<T>>, TopologyElement
- All Known Subinterfaces:
- SPLStream
public interface TStream<T> extends TopologyElement, Placeable<TStream<T>>
ATStreamis a declaration of a continuous sequence of tuples. A connected topology of streams and functional transformations is built usingTopology.
Generic methods on this interface provide the ability tofilter,transformorsinkthis declared stream using a function.
Utility methods in thecom.ibm.streams.topology.streamspackage provide specific source streams, or transformations on streams with specific types.TStreamimplementsPlaceableto allow placement directives against the processing that produced this stream. For example, calling aPlaceablemethod on the stream returned fromfilter(Predicate)will apply to the container that is executing thePredicatepassed intofilter().
When multiple streams are produced by a method (e.g.split(int, ToIntFunction)placement directives are common to all of the produced streams.
-
-
Nested Class Summary
Nested Classes Modifier and Type Interface and Description static classTStream.RoutingEnumeration for routing tuples to parallel channels.
-
Method Summary
All Methods Instance Methods Abstract Methods Modifier and Type Method and Description TStream<T>asType(java.lang.Class<T> tupleTypeClass)Return a strongly typed reference to this stream.TStream<T>autonomous()Return a stream matching this stream whose subsequent processing will execute in an autonomous region.com.ibm.streamsx.topology.builder.BInputPortconnectTo(com.ibm.streamsx.topology.builder.BOperatorInvocation receivingBop, boolean functional, com.ibm.streamsx.topology.builder.BInputPort input)Internal method.TStream<T>endLowLatency()Return a TStream that is no longer guaranteed to run in the same process as the calling stream.TStream<T>endParallel()Ends a parallel region by merging the channels into a single stream.TStream<T>filter(Predicate<T> filter)Declare a new stream that filters tuples from this stream.<U> TStream<U>flatMap(Function<T,java.lang.Iterable<U>> mapper)Declare a new stream that maps tuples from this stream into one or more (or zero) tuples of a different typeU.TSinkforEach(Consumer<T> action)Sink (terminate) this stream.java.lang.Class<T>getTupleClass()Class of the tuples on this stream, if known.java.lang.reflect.TypegetTupleType()Type of the tuples on this stream.TStream<T>isolate()Return a stream whose immediate subsequent processing will execute in a separate operating system process from this stream's processing.<J,U,K> TStream<J>join(Function<T,K> keyer, TWindow<U,K> window, BiFunction<T,java.util.List<U>,J> joiner)Join this stream with a partitioned window of typeUwith key typeK.<J,U> TStream<J>join(TWindow<U,?> window, BiFunction<T,java.util.List<U>,J> joiner)Join this stream with window of typeU.<J,U,K> TStream<J>joinLast(Function<? super T,? extends K> keyer, TStream<U> lastStream, Function<? super U,? extends K> lastStreamKeyer, BiFunction<T,U,J> joiner)Join this stream with the last tuple seen on a stream of typeUwith partitioning.<J,U> TStream<J>joinLast(TStream<U> lastStream, BiFunction<T,U,J> joiner)Join this stream with the last tuple seen on a stream of typeU.TWindow<T,java.lang.Object>last()Declare aTWindowthat continually represents the last tuple on this stream.TWindow<T,java.lang.Object>last(int count)Declare aTWindowthat continually represents the lastcounttuples seen on this stream.TWindow<T,java.lang.Object>last(long time, java.util.concurrent.TimeUnit unit)Declare aTWindowthat continually represents the lasttimeseconds of tuples (in the given timeunit) on this stream.TWindow<T,java.lang.Object>last(Supplier<java.lang.Integer> count)Declare aTWindowthat continually represents the lastcounttuples seen on this stream.TWindow<T,java.lang.Object>lastSeconds(Supplier<java.lang.Integer> time)Declare aTWindowthat continually represents the lasttimeseconds of tuples on this stream.TStream<T>lowLatency()Return a stream that is guaranteed to run in the same process as the calling TStream.<U> TStream<U>map(Function<T,U> mapper)Declare a new stream that maps each tuple from this stream into one (or zero) tuple of a different typeU.TStream<T>modify(UnaryOperator<T> modifier)Declare a new stream that modifies each tuple from this stream into one (or zero) tuple of the same typeT.<U> TStream<U>multiTransform(Function<T,java.lang.Iterable<U>> transformer)Declare a new stream that maps tuples from this stream into one or more (or zero) tuples of a different typeU.com.ibm.streamsx.topology.builder.BOutputoutput()Internal method.TStream<T>parallel(int width)Parallelizes the stream into a a fixed number of parallel channels using round-robin distribution.TStream<T>parallel(Supplier<java.lang.Integer> width, Function<T,?> keyer)Parallelizes the stream into a number of parallel channels using key based distribution.TStream<T>parallel(Supplier<java.lang.Integer> width, TStream.Routing routing)Parallelizes the stream intowidthparallel channels.TStream<T>parallel(Supplier<java.lang.Integer> width)Parallelizes the stream intowidthparallel channels.TSinkprint()Print each tuple onSystem.out.voidpublish(java.lang.String topic, boolean allowFilter)Publish tuples from this stream for consumption by other IBM Streams applications.voidpublish(java.lang.String topic)Publish tuples from this stream for consumption by other IBM Streams applications.voidpublish(Supplier<java.lang.String> topic, boolean allowFilter)Publish tuples from this stream for consumption by other IBM Streams applications.voidpublish(Supplier<java.lang.String> topic)Publish tuples from this stream for consumption by other IBM Streams applications.TStream<T>sample(double fraction)Return a stream that is a random sample of this stream.TStream<T>setConsistent(ConsistentRegionConfig config)Set the operator that is the source of this stream to be the start of a consistent region to support at least once and exactly once processing.TStream<T>setParallel(Supplier<java.lang.Integer> width)Sets the current stream as the start of a parallel region.TSinksink(Consumer<T> sinker)Terminate this stream.java.util.List<TStream<T>>split(int n, ToIntFunction<T> splitter)Distribute a stream's tuples amongnstreams as specified by asplitter.TStream<T>throttle(long delay, java.util.concurrent.TimeUnit unit)Throttle a stream by ensuring any tuple is submitted with leastdelayfrom the previous tuple.<U> TStream<U>transform(Function<T,U> transformer)Declare a new stream that transforms each tuple from this stream into one (or zero) tuple of a different typeU.TStream<T>union(java.util.Set<TStream<T>> others)Create a stream that is a union of this stream andothersstreams of the same typeT.TStream<T>union(TStream<T> other)Create a stream that is a union of this stream andotherstream of the same typeT.TWindow<T,java.lang.Object>window(TWindow<?,?> configWindow)Declare aTWindowon this stream that has the same configuration as another window.-
Methods inherited from interface com.ibm.streamsx.topology.context.Placeable
addResourceTags, colocate, getInvocationName, getResourceTags, invocationName, isPlaceable, operator
-
Methods inherited from interface com.ibm.streamsx.topology.TopologyElement
builder, topology
-
-
-
-
Method Detail
-
filter
TStream<T> filter(Predicate<T> filter)
Declare a new stream that filters tuples from this stream. Each tupleton this stream will appear in the returned stream iffilter.test(t)returnstrue. Iffilter.test(t)returnsfalsethen thentwill not appear in the returned stream.Examples of filtering out all empty strings from stream
sof typeString// Java 8 - Using lambda expression TStream<String> s = ... TStream<String> filtered = s.filter(t -> !t.isEmpty()); // Java 7 - Using anonymous class TStream<String> s = ... TStream<String> filtered = s.filter(new Predicate<String>() { @Override public boolean test(String t) { return !t.isEmpty(); }} );- Parameters:
filter- Filtering logic to be executed against each tuple.- Returns:
- Filtered stream
- See Also:
split(int, ToIntFunction)
-
split
java.util.List<TStream<T>> split(int n, ToIntFunction<T> splitter)
Distribute a stream's tuples amongnstreams as specified by asplitter.For each tuple on the stream,
splitter.applyAsInt(tuple)is called. The return valuerdetermines the destination stream:if r < 0 the tuple is discarded else it is sent to the stream at position (r % n) in the returned array.
Each split
TStreamis exposed by the API. The user has full control over the each stream's processing pipeline. Each stream's pipeline must be declared explicitly. Each stream can have different processing pipelines.An N-way
split()is logically equivalent to a collection of Nfilter()invocations, each with apredicateto select the tuples for its stream.split()is more efficient. Each tuple is analyzed only once by a singlesplitterinstance to identify the destination stream. For example, these are logically equivalent:List<TStream<String>> streams = stream.split(2, mySplitter()); TStream<String> stream0 = stream.filter(myPredicate("ch0")); TStream<String> stream1 = stream.filter(myPredicate("ch1"));parallel(Supplier, Routing)also distributes a stream's tuples among N-channels but it presents a different usage model. The user specifies a single logical processing pipeline and the logical pipeline is transparently replicated for each of the channels. The API does not provide access to the individual channels in the logical stream.endParallel()declares the end of the parallel pipeline and combines all of the channels into a single resulting stream.Example of splitting a stream of tuples by their severity attribute:
interface MyType { String severity; ... }; TStream<MyType> s = ... List<<TStream<MyType>> splits = s.split(3, new ToIntFunction<MyType>() { @Override public int applyAsInt(MyType tuple) { if(tuple.severity.equals("high")) return 0; else if(tuple.severity.equals("low")) return 1; else return 2; }} ); splits.get(0). ... // high severity processing pipeline splits.get(1). ... // low severity processing pipeline splits.get(2). ... // "other" severity processing pipeline- Parameters:
n- the number of output streamssplitter- the splitter function- Returns:
- List of
nstreams - Throws:
java.lang.IllegalArgumentException- ifn <= 0- See Also:
parallel(Supplier, Routing)
-
transform
<U> TStream<U> transform(Function<T,U> transformer)
Declare a new stream that transforms each tuple from this stream into one (or zero) tuple of a different typeU. For each tupleton this stream, the returned stream will contain a tuple that is the result oftransformer.apply(t)when the return is notnull. Iftransformer.apply(t)returnsnullthen no tuple is submitted to the returned stream fort.Examples of transforming a stream containing numeric values as
Stringobjects into a stream ofDoublevalues.// Java 8 - Using lambda expression TStream<String> strings = ... TStream<Double> doubles = strings.transform(v -> Double.valueOf(v)); // Java 8 - Using method reference TStream<String> strings = ... TStream<Double> doubles = strings.transform(Double::valueOf); // Java 7 - Using anonymous class TStream<String> strings = ... TStream<Double> doubles = strings.transform(new FunctionThis function is equivalent to
map(Function).- Parameters:
transformer- Transformation logic to be executed against each tuple.- Returns:
- Stream that will contain tuples of type
Utransformed from this stream's tuples.
-
map
<U> TStream<U> map(Function<T,U> mapper)
Declare a new stream that maps each tuple from this stream into one (or zero) tuple of a different typeU. For each tupleton this stream, the returned stream will contain a tuple that is the result ofmapper.apply(t)when the return is notnull. Ifmapper.apply(t)returnsnullthen no tuple is submitted to the returned stream fort.Examples of mapping a stream containing numeric values as
Stringobjects into a stream ofDoublevalues.// Java 8 - Using lambda expression TStream<String> strings = ... TStream<Double> doubles = strings.map(v -> Double.valueOf(v)); // Java 8 - Using method reference TStream<String> strings = ... TStream<Double> doubles = strings.map(Double::valueOf); // Java 7 - Using anonymous class TStream<String> strings = ... TStream<Double> doubles = strings.map(new FunctionThis function is equivalent to
transform(Function). The typical term in most apis ismap.- Parameters:
mapper- Mapping logic to be executed against each tuple.- Returns:
- Stream that will contain tuples of type
Umapped from this stream's tuples. - Since:
- 1.7
-
modify
TStream<T> modify(UnaryOperator<T> modifier)
Declare a new stream that modifies each tuple from this stream into one (or zero) tuple of the same typeT. For each tupleton this stream, the returned stream will contain a tuple that is the result ofmodifier.apply(t)when the return is notnull. The function may return the same reference as its inputtor a different object of the same type. Ifmodifier.apply(t)returnsnullthen no tuple is submitted to the returned stream fort.Example of modifying a stream
Stringvalues by adding the suffix 'extra'.TStream<String> strings = ... TStream<String> modifiedStrings = strings.modify(new UnaryOperator() { @Override public String apply(String tuple) { return tuple.concat("extra"); }}); This method is equivalent to
transform(Function<T,T> modifier).- Parameters:
modifier- Modifier logic to be executed against each tuple.- Returns:
- Stream that will contain tuples of type
Tmodified from this stream's tuples.
-
flatMap
<U> TStream<U> flatMap(Function<T,java.lang.Iterable<U>> mapper)
Declare a new stream that maps tuples from this stream into one or more (or zero) tuples of a different typeU. For each tupleton this stream, the returned stream will contain all non-null tuples in theIterator<U>that is the result ofmapper.apply(t). Tuples will be added to the returned stream in the order the iterator returns them.
If the return is null or an empty iterator then no tuples are added to the returned stream for input tuplet.Examples of transforming a stream containing lines of text into a stream of words split out from each line. The order of the words in the stream will match the order of the words in the lines.
// Java 8 - Using lambda expression TStream<String> lines = ... TStream<String> words = lines.multiTransform( line -> Arrays.asList(line.split(" "))); // Java 7 - Using anonymous class TStream<String> lines = ... TStream<String> words = lines.multiTransform(new Functionapply(String line) { return Arrays.asList(line.split(" ")); }}); - Parameters:
mapper- Mapper logic to be executed against each tuple.- Returns:
- Stream that will contain tuples of type
Umapped from this stream's tuples. - Since:
- 1.7
-
multiTransform
<U> TStream<U> multiTransform(Function<T,java.lang.Iterable<U>> transformer)
Declare a new stream that maps tuples from this stream into one or more (or zero) tuples of a different typeU.This function is equivalent to
flatMap(Function).- Parameters:
transformer- Mapper logic to be executed against each tuple.- Returns:
- Stream that will contain tuples of type
Umapped from this stream's tuples.
-
forEach
TSink forEach(Consumer<T> action)
Sink (terminate) this stream. For each tupleton this streamaction.accept(t)will be called. This is typically used to send information to external systems, such as databases or dashboards.Example of terminating a stream of
Stringtuples by printing them toSystem.out.TStream<String> values = ... values.forEach(new Consumer() { @Override public void accept(String tuple) { System.out.println(tuple); } }); - Parameters:
action- Action to be executed against each tuple on this stream.- Returns:
- the sink element
- Since:
- 1.7
-
sink
TSink sink(Consumer<T> sinker)
Terminate this stream.This function is equivalent to
forEach(Consumer).- Parameters:
sinker- Action to be executed against each tuple on this stream.- Returns:
- the sink element
-
union
TStream<T> union(TStream<T> other)
Create a stream that is a union of this stream andotherstream of the same typeT. Any tuple on this stream orotherwill appear on the returned stream.
No ordering of tuples across this stream andotheris defined, thus the return stream is unordered.
Ifotheris this stream or keyed version of this stream thenthisis returned as a stream cannot be unioned with itself.- Parameters:
other- Stream to union with this stream.- Returns:
- Stream that will contain tuples from this stream and
other.
-
union
TStream<T> union(java.util.Set<TStream<T>> others)
Create a stream that is a union of this stream andothersstreams of the same typeT. Any tuple on this stream or any ofotherswill appear on the returned stream.
No ordering of tuples across this stream andothersis defined, thus the return stream is unordered.
If others does not contain any streams thenthisis returned.
A stream or a keyed version of a stream cannot be unioned with itself, so any stream that is represented multiple times inothersor this stream will be reduced to a single copy of itself.
In the case that no stream is to be unioned with this stream thenthisis returned (for example,othersis empty or only contains the same logical stream asthis.- Parameters:
others- Streams to union with this stream.- Returns:
- Stream containing tuples from this stream and
others.
-
print
TSink print()
Print each tuple onSystem.out. For each tupleton this streamSystem.out.println(t.toString())will be called.
-
getTupleClass
java.lang.Class<T> getTupleClass()
Class of the tuples on this stream, if known. Will be the same asgetTupleType()if it is aClassobject.- Returns:
- Class of the tuple on this stream,
nullifgetTupleType()is not aClassobject.
-
getTupleType
java.lang.reflect.Type getTupleType()
Type of the tuples on this stream. Can be null if no type knowledge can be determined.- Returns:
- Type of the tuples on this stream,
nullif no type knowledge could be determined
-
join
<J,U> TStream<J> join(TWindow<U,?> window, BiFunction<T,java.util.List<U>,J> joiner)
Join this stream with window of typeU. For each tuple on this stream, it is joined with the contents ofwindow. Each tuple is passed intojoinerand the return value is submitted to the returned stream. If call returns null then no tuple is submitted.- Parameters:
joiner- Join function.- Returns:
- A stream that is the results of joining this stream with
window.
-
join
<J,U,K> TStream<J> join(Function<T,K> keyer, TWindow<U,K> window, BiFunction<T,java.util.List<U>,J> joiner)
Join this stream with a partitioned window of typeUwith key typeK. For each tuple on this stream, it is joined with the contents ofwindowfor the keykeyer.apply(tuple). Each tuple is passed intojoinerand the return value is submitted to the returned stream. If call returns null then no tuple is submitted.- Parameters:
keyer- Key function for this stream to match the window's key.window- Keyed window to join this stream with.joiner- Join function.- Returns:
- A stream that is the results of joining this stream with
window.
-
joinLast
<J,U,K> TStream<J> joinLast(Function<? super T,? extends K> keyer, TStream<U> lastStream, Function<? super U,? extends K> lastStreamKeyer, BiFunction<T,U,J> joiner)
Join this stream with the last tuple seen on a stream of typeUwith partitioning. For each tuple on this stream, it is joined with the last tuple seen onlastStreamwith a matching key (of typeK).
Each tupleton this stream will match the last tupleuonlastStreamifkeyer.apply(t).equals(lastStreamKeyer.apply(u))is true.
The assumption is made that the key classes correctly implement the contract forequalsandhashCode().Each tuple is passed into
joinerand the return value is submitted to the returned stream. If call returns null then no tuple is submitted.- Parameters:
keyer- Key function for this streamlastStream- Stream to join with.lastStreamKeyer- Key function forlastStreamjoiner- Join function.- Returns:
- A stream that is the results of joining this stream with
lastStream.
-
joinLast
<J,U> TStream<J> joinLast(TStream<U> lastStream, BiFunction<T,U,J> joiner)
Join this stream with the last tuple seen on a stream of typeU. For each tuple on this stream, it is joined with the last tuple seen onlastStream. Each tuple is passed intojoinerand the return value is submitted to the returned stream. If call returns null then no tuple is submitted.
This is a simplified version ofjoin(TWindow, BiFunction)where instead the window contents are passed as a single tuple of typeUrather than a list containing one tuple. If no tuple has been seen onlastStreamthennullwill be passed as the second argument tojoiner.- Parameters:
lastStream- Stream to join with.joiner- Join function.- Returns:
- A stream that is the results of joining this stream with
lastStream.
-
last
TWindow<T,java.lang.Object> last(long time, java.util.concurrent.TimeUnit unit)
Declare aTWindowthat continually represents the lasttimeseconds of tuples (in the given timeunit) on this stream. If no tuples have been seen on the stream in the lasttimeseconds then the window will be empty.
The window has a single partition that always contains the lasttimeseconds of tuples seen on this stream
A key based partitioned window can be created from the returned window usingTWindow.key(Function)orTWindow.key(). When the window is partitioned each partition independently maintains the lasttimeseconds of tuples for each key seen on this stream.- Parameters:
time- Time size of the windowunit- Unit fortime- Returns:
- Window on this stream representing the last
timeseconds.
-
lastSeconds
TWindow<T,java.lang.Object> lastSeconds(Supplier<java.lang.Integer> time)
Declare aTWindowthat continually represents the lasttimeseconds of tuples on this stream. Same aslast(long,TimeUnit)except thetimeis specified with aSupplier<Integer>such as one created byTopology.createSubmissionParameter(String, Class).- Parameters:
time- Time size of the window in seconds- Returns:
- Window on this stream representing the last
timeseconds.
-
last
TWindow<T,java.lang.Object> last(Supplier<java.lang.Integer> count)
Declare aTWindowthat continually represents the lastcounttuples seen on this stream. Same aslast(int)except thecountis specified with aSupplier<Integer>such as one created byTopology.createSubmissionParameter(String, Class).- Parameters:
count- Tuple size of the window- Returns:
- Window on this stream representing the last
counttuples.
-
last
TWindow<T,java.lang.Object> last(int count)
Declare aTWindowthat continually represents the lastcounttuples seen on this stream. If the stream has not yet seencounttuples then it will contain all of the tuples seen on the stream, which will be less thancount. If no tuples have been seen on the stream then the window will be empty.
The window has a single partition that always contains the lastcounttuples seen on this stream.
The window has a single partition that always contains the last tuple seen on this stream.
A key based partitioned window can be created from the returned window usingTWindow.key(Function)orTWindow.key(). When the window is partitioned each partition independently maintains the lastcounttuples for each key seen on this stream.- Parameters:
count- Tuple size of the window- Returns:
- Window on this stream representing the last
counttuples.
-
last
TWindow<T,java.lang.Object> last()
Declare aTWindowthat continually represents the last tuple on this stream. If no tuples have been seen on the stream then the window will be empty.
The window has a single partition that always contains the last tuple seen on this stream.
A key based partitioned window can be created from the returned window usingTWindow.key(Function)orTWindow.key(). When the window is partitioned each partition independently maintains the last tuple for each key seen on this stream.- Returns:
- Window on this stream representing the last tuple.
-
window
TWindow<T,java.lang.Object> window(TWindow<?,?> configWindow)
Declare aTWindowon this stream that has the same configuration as another window.
The window has a single partition.
A key based partitioned window can be created from the returned window usingTWindow.key(Function)orTWindow.key().- Parameters:
configWindow- Window to copy the configuration from.- Returns:
- Window on this stream with the same configuration as
configWindow.
-
publish
void publish(java.lang.String topic)
Publish tuples from this stream for consumption by other IBM Streams applications. Applications consume published streams using:-
Topology.subscribe(String, Class)for Java Streams applications. -
com.ibm.streamsx.topology.topic::Subscribeoperator for SPL Streams applications. -
com.ibm.streamsx.topology.topic::FilteredSubscribeoperator for SPL Streams applications subscribing to a subset of the published tuples.
A subscriber matches to a publisher if:- The topic name is an exact match, and:
-
For JSON streams (
TStream<JSONObject>) the subscription is to a JSON stream. -
For Java streams (
TStream<T>) the declared Java type (T) of the stream is an exact match. -
For
SPL streamstheSPL schemais an exact match.
This method is identical topublish(topic, false).A topic name:
- must not be zero length
- must not contain the nul character (
�) - must not contain wild card characters number sign (
‘#’ #) or the plus sign (‘+’ +)
‘/’ /) is used to separate each level within a topic tree and provide a hierarchical structure to the topic names. The use of the topic level separator is significant when either of the two wildcard characters is encountered in topic filters specified by subscribing applications. Topic level separators can appear anywhere in a topic filter or topic name. Adjacent topic level separators indicate a zero length topic level.The type of the stream must be known to ensure that
subscribersmatch on the Java type. Where possible the type of a stream is determined automatically, but due to Java type erasure this is not always possible. A stream can be assigned its type usingasType(Class). For example, with a stream containing tuples of typeLocationit can be correctly published as follows:TStream<Location> locations = ... locations.asType(Location.class).publish("location/bus");- Parameters:
topic- Topic name to publish tuples to.- Throws:
java.lang.IllegalStateException- Type of the stream is not known.- See Also:
Topology.subscribe(String, Class),SPLStreams.subscribe(TopologyElement, String, com.ibm.streams.operator.StreamSchema)
-
-
publish
void publish(Supplier<java.lang.String> topic)
Publish tuples from this stream for consumption by other IBM Streams applications. Differs frompublish(String)in that it supportstopicas a submission time parameter, for example using the topic defined by the submission parametereventTopic:TStreamevents = ... Supplier topicParam = topology.createSubmissionParameter("eventTopic", String.class); topology.publish(topicParam); - Parameters:
topic- Topic name to publish tuples to.- Since:
- 1.8
- See Also:
publish(String)
-
publish
void publish(java.lang.String topic, boolean allowFilter)Publish tuples from this stream for consumption by other IBM Streams applications. Applications consume published streams using:-
Topology.subscribe(String, Class)for Java Streams applications. -
com.ibm.streamsx.topology.topic::Subscribeoperator for SPL Streams applications.
TStream<JSONObject>- JSON tuples, SPL schema ofJson.TStream<String>- String tuples, SPL schema ofString.TStream<com.ibm.streams.operator.types.XML>, SPL schema ofXml.TStream<com.ibm.streams.operator.types.Blob>, SPL schema ofBlob.
A subscriber matches to a publisher if:- The topic name is an exact match, and:
-
For JSON streams (
TStream<JSONObject>) the subscription is to a JSON stream. -
For Java streams (
TStream<T>) the declared Java type (T) of the stream is an exact match. -
For
SPL streamstheSPL schemais an exact match.
allowFilterspecifies if SPL filters can be pushed from a subscribing application to the publishing application. Executing filters on the publishing side reduces network communication between the publisher and the subscriber.
WhenallowFilterisfalseSPL filters cannot be pushed to the publishing application.
WhenallowFilteristrueSPL filters are executed in the publishing applications.
Regardless of the setting ofallowFilteran invocation ofTopology.subscribe(String, Class)orcom.ibm.streamsx.topology.topic::Subscribesubscribes to all published tuples.
allowFiltercan only be set to true for:- This stream is an instance of
SPLStream. - This stream is an instance of
TStream<String>.
A topic name:
- must not be zero length
- must not contain the nul character (
�) - must not contain wild card characters number sign (
‘#’ #) or the plus sign (‘+’ +)
‘/’ /) is used to separate each level within a topic tree and provide a hierarchical structure to the topic names. The use of the topic level separator is significant when either of the two wildcard characters is encountered in topic filters specified by subscribing applications. Topic level separators can appear anywhere in a topic filter or topic name. Adjacent topic level separators indicate a zero length topic level.The type of the stream must be known to ensure that
subscribersmatch on the Java type. Where possible the type of a stream is determined automatically, but due to Java type erasure this is not always possible. A stream can be assigned its type usingasType(Class). For example, with a stream containing tuples of typeLocationit can be correctly published as follows:TStream<Location> locations = ... locations.asType(Location.class).publish("location/bus");- Parameters:
topic- Topic name to publish tuples to.allowFilter- Allow SPL filters specified by SPL application to be executed in the publishing application.- Throws:
java.lang.IllegalStateException- Type of the stream is not known.- See Also:
Topology.subscribe(String, Class),asType(Class),SPLStreams.subscribe(TopologyElement, String, com.ibm.streams.operator.StreamSchema)
-
-
publish
void publish(Supplier<java.lang.String> topic, boolean allowFilter)
Publish tuples from this stream for consumption by other IBM Streams applications. Differs frompublish(String, boolean)in that it supportstopicas a submission time parameter, for example using the topic defined by the submission parametereventTopic:TStreamevents = ... Supplier topicParam = topology.createSubmissionParameter("eventTopic", String.class); topology.publish(topicParam, false); - Parameters:
topic- Topic name to publish tuples to.allowFilter- Allow SPL filters specified by SPL application to be executed.- Since:
- 1.8
- See Also:
publish(String, boolean)
-
parallel
TStream<T> parallel(int width)
Parallelizes the stream into a a fixed number of parallel channels using round-robin distribution.
Tuples are routed to the parallel channels in around-robin fashion.
Subsequent transformations on the returned stream will be executedwidthchannels untilendParallel()is called or the stream terminates.
Seeparallel(Supplier, Routing)for more information.- Parameters:
width- The degree of parallelism in the parallel region.- Returns:
- A reference to a stream for which subsequent transformations will be
executed in parallel using
widthchannels.
-
parallel
TStream<T> parallel(Supplier<java.lang.Integer> width)
Parallelizes the stream intowidthparallel channels. Same asparallel(int)except thewidthis specified with aSupplier<Integer>such as one created byTopology.createSubmissionParameter(String, Class).- Parameters:
width- The degree of parallelism in the parallel region.- Returns:
- A reference to a stream for which subsequent transformations will be
executed in parallel using
widthchannels.
-
parallel
TStream<T> parallel(Supplier<java.lang.Integer> width, TStream.Routing routing)
Parallelizes the stream intowidthparallel channels. Tuples are routed to the parallel channels based on theTStream.Routingparameter.
IfTStream.Routing.ROUND_ROBINis specified the tuples are routed to parallel channels such that an even distribution is maintained.
IfTStream.Routing.HASH_PARTITIONEDis specified then thehashCode()of the tuple is used to route the tuple to a corresponding channel, so that all tuples with the same hash code are sent to the same channel.
IfTStream.Routing.KEY_PARTITIONEDis specified each tuple is is taken to be its own key and is routed so that all tuples with the same key are sent to the same channel. This is equivalent to callingparallel(Supplier, Function)with an identity function.
Source operations may be parallelized as well, refer tosetParallel(Supplier)for more information.
Given the following code:
The following graph is created:TStream<String> myStream = topology.source(...); TStream<String> parallelStart = myStream.parallel(of(3), TStream.Routing.ROUND_ROBIN); TStream<String> inParallel = parallelStart.map(...); TStream<String> joinedParallelStreams = inParallel.endParallel(); joinedParallelStreams.print();
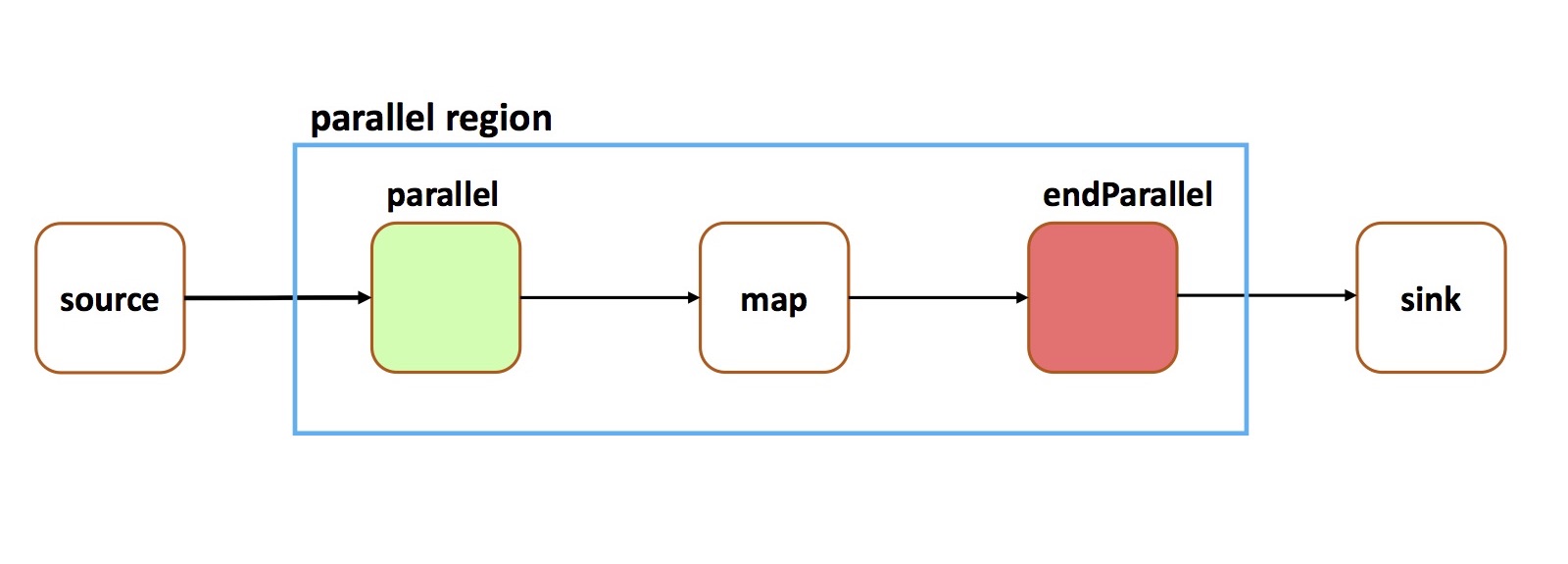
Callingparallel(3)creates three parallel channels. Each of the 3 channels contains separate instantiations of the operations (in this case, just map) declared in the region. Such stream operations are run in parallel as follows:
Execution Context Parallel Behavior Standalone Each parallel channel is separately executed by one or more threads. The number of threads executing a channel is exactly 1 thread per input to the channel. Distributed A parallel channel is never run in the same process as another parallel channel. Furthermore, a single parallel channel may executed across multiple processes, as determined by the Streams runtime. Streaming Analytics service Same as Distributed. Embedded All parallel information is ignored, and the application is executed without any added parallelism.
A parallel region can have multiple inputs and multiple outputs. An input to a parallel region is a stream on whichparallel(int)has been called, and an output is a stream on whichendParallel()has been called. A parallel region with multiple inputs is created if a stream in one parallel region connects with a stream in another parallel region.
Two streams "connect" if:- One stream invokes
union(TStream)using the other as a parameter. - Both streams are used as inputs to an SPL operator created through
invokeOperatorwhich has multiple input ports.
For example, the following code connects two separate parallel regions into a single parallel region with multiple inputs:
This code results in the following graph:TStream<String> firstStream = topology.source(...); TStream<String> secondStream = topology.source(...); TStream<String> firstParallelStart = firstStream.parallel(of(3), TStream.Routing.ROUND_ROBIN); TStream<String> secondParallelStart = secondStream.parallel(of(3), TStream.Routing.ROUND_ROBIN); TStream<String> fistMapOutput = firstParallelStart.map(...); TStream<String> unionedStreams = firstMapOutput.union(secondParallelStart); TStream<String> secondMapOutput = unionedStreams.map(...); TStream<String> nonParallelStream = secondMapOutput.endParallel(); nonParallelStream.print();
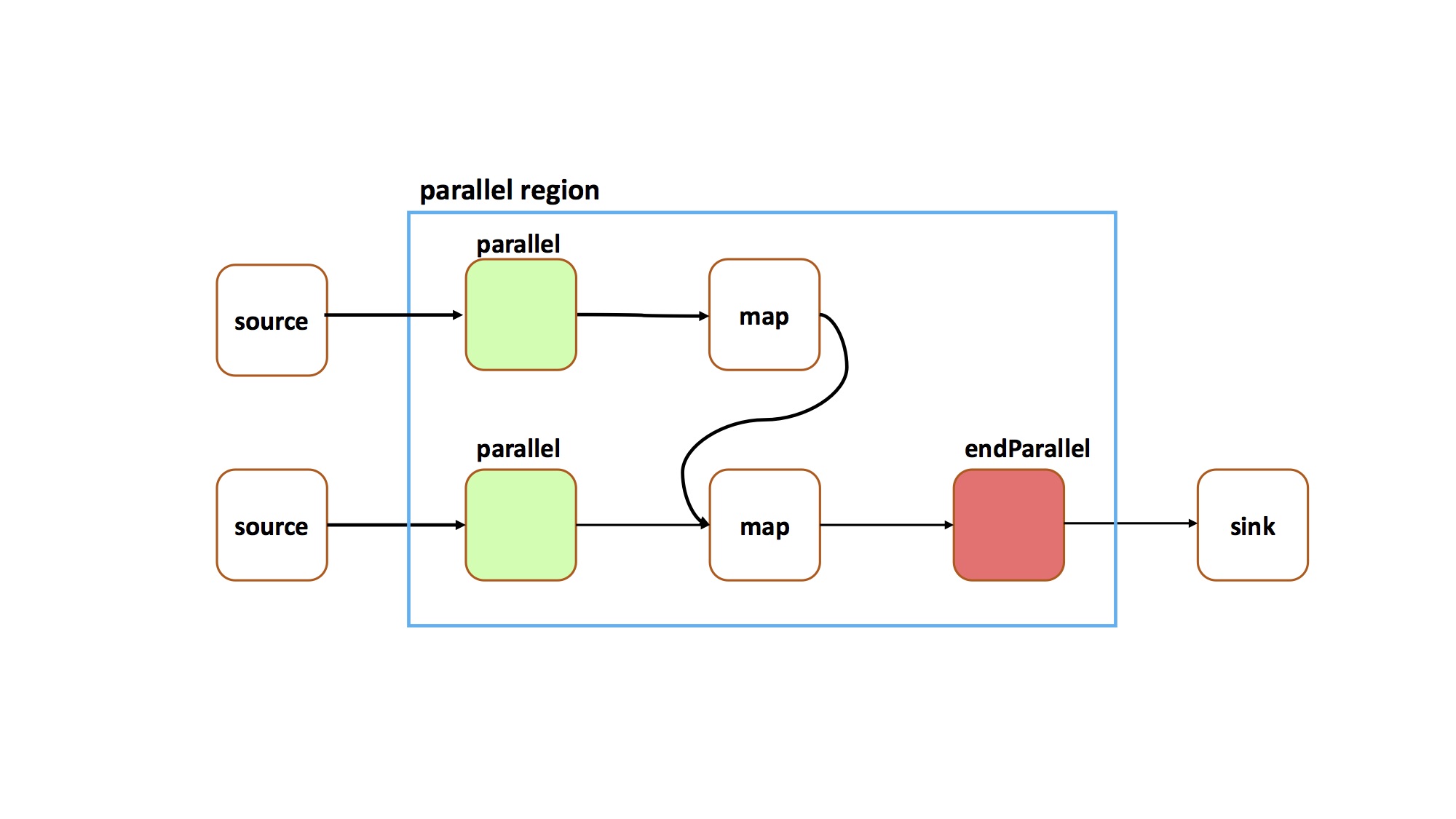
When creating a parallel region with multiple inputs, the different inputs must all have the same value for the degree of parallelism. For example, it can not be the case that one parallel region input specifies a width of 4, while another input to the same region specifies a width of 5. Additionally, if a submission time parameter is used to specify the width of a parallel region, then different inputs to that region must all use the same submission time parameter object.
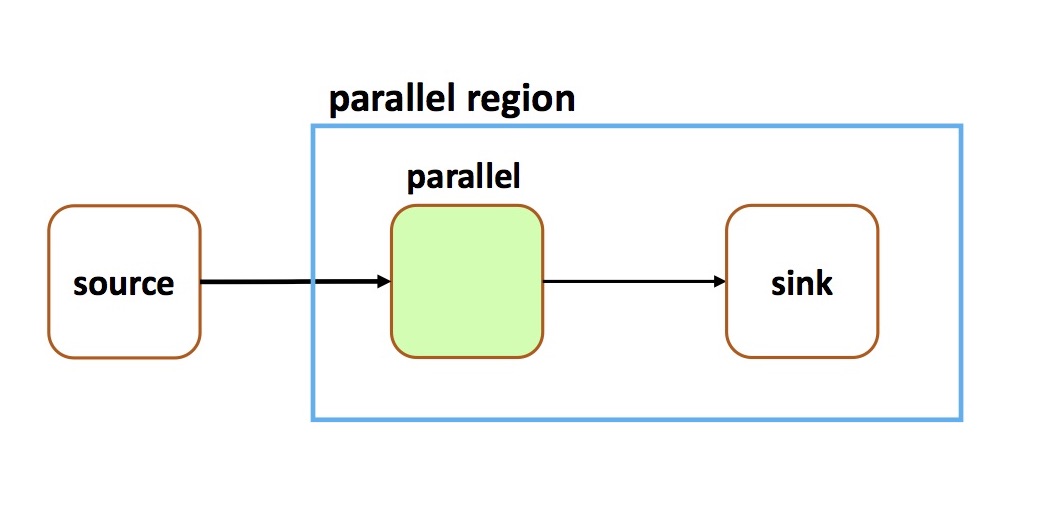
A parallel region may contain a sink; it is not required that a parallel region have an output stream. The following defines a sink in a parallel region:
In the above code, the parallel region is implicitly ended by the sink, without callingTStream<String> myStream = topology.source(...); TStream<String> myParallelStream = myStream.parallel(6); myParallelStream.print();endParallel()This results in the following graph:
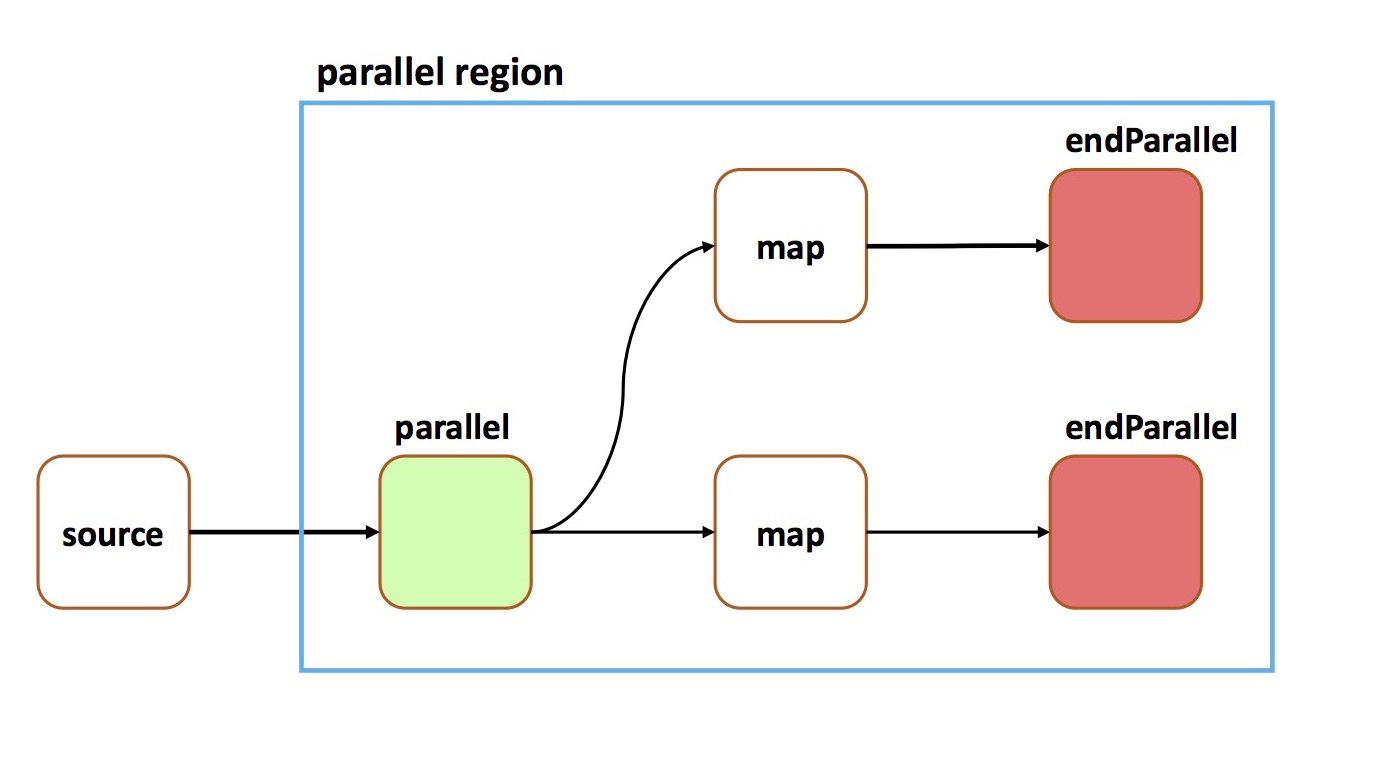
A parallel region with multiple output streams can be created by invokingendParallel()on multiple streams within the same parallel region. For example, the following code defines a parallel region with multiple output streams:
The above code would yield the following graph:TStream<String> myStream = topology.source(...); TStream<String> parallelStart = myStream.parallel(of(3), TStream.Routing.ROUND_ROBIN); TStream<String> firstInParallel = parallelStart.map(...); TStream<String> secondInParallel = parallelStart.map(...); TStream<String> firstParallelOutput = firstInParallel.endParallel(); TStream<String> secondParallelOutput = secondInParallel.endParallel();
When a stream outside of a parallel region connects to a stream inside of a parallel region, the outside stream and all of its prior operations implicitly become part of the parallel region. For example, the following code connects a stream outside a parallel region to a stream inside of a parallel region.
Once connected, the stream outside of the parallel region (and all of its prior operations) becomes part of the parallel region:TStream<String> firstStream = topology.source(...); TStream<String> secondStream = topology.source(...); TStream<String> parallelStream = firstStream.parallel(of(3), TStream.Routing.ROUND_ROBIN); TStream<String> secondParallelStart = TStream<String> firstInParallel = firstParallelStart.map(...); TStream<String> secondInParallel = secondParallelStart.map(...); TStream<String> unionStream = firstInParallel.union(secondInParallel); TStream<String> nonParallelStream = unionStream.endParallel(); nonParallelStream.print();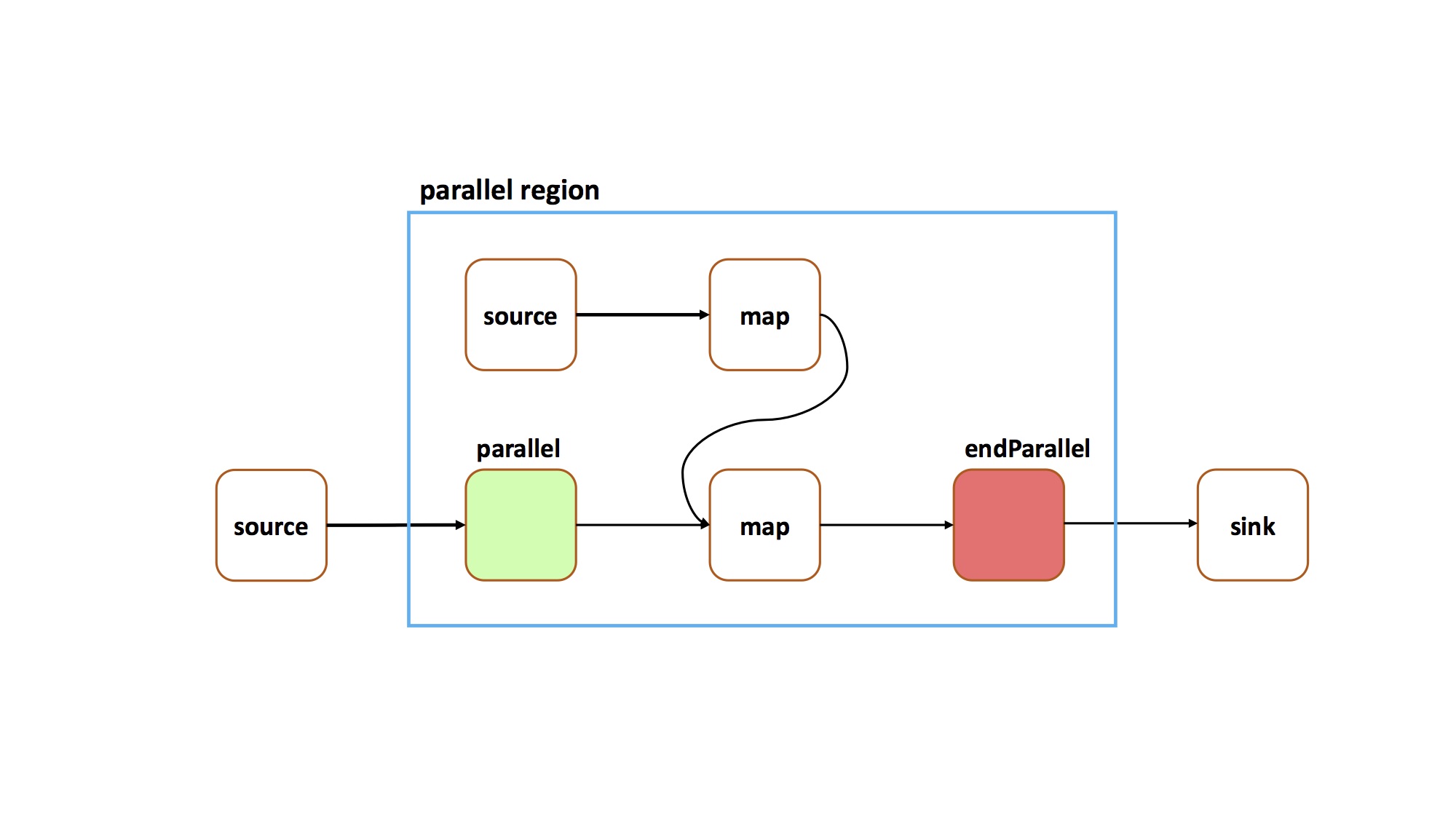
The Streams runtime supports the nesting of parallel regions inside of another parallel region. A parallel region will become nested inside of another parallel region in one of two cases:-
If
parallel(int)is invoked on a stream which is already inside of a parallel region. - A stream inside of a parallel region becomes connected to a stream that has a parallel region in its previous operations.
parallel(int)twice on the same stream creates a nested parallel region as follows:
Results in a graph of the following structure:TStream<String> stream = topology.source(...); stream.parallel(3).map(...).parallel(3).map(...).endParallel().endParallel();
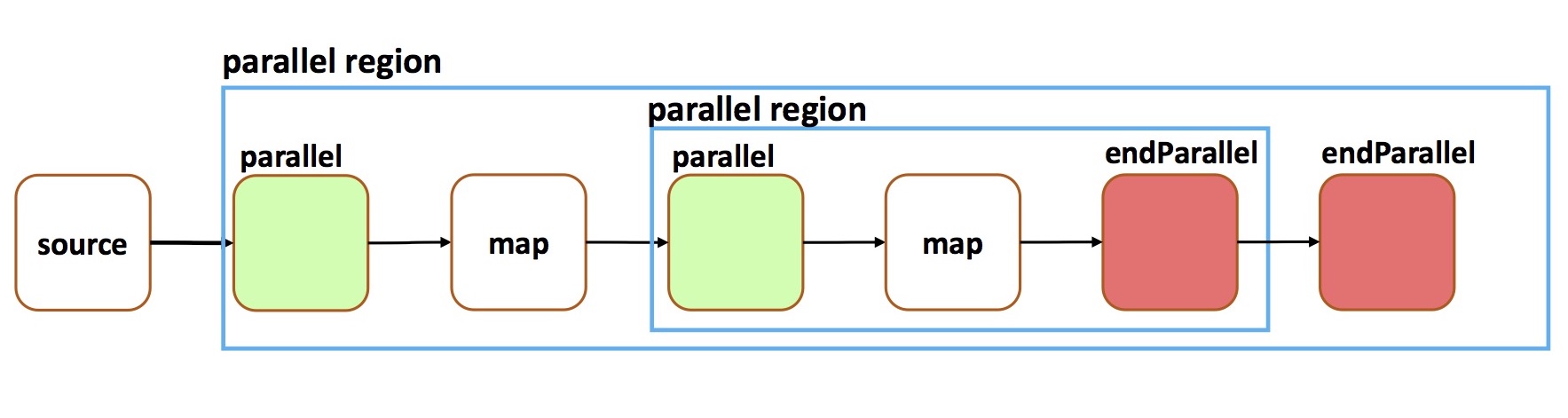
Whereas the first map operation is instantiated exactly 3 times due toparallel(3), the second map operation is instantiated a total of 9 times since each of the 3 enclosing parallel channels holds 3 nested parallel channels. TheTStream#Routingconfigurations of the enclosing and nested parallel regions do not need to match.
As previously mentioned, nesting also occurs when a stream inside of a parallel region becomes connected to a stream that has a parallel region in its previous operations. The following code creates such a situation:
This results in the following graph structure:TStream<String> streamToJoin = topology.source(...); streamToJoin.setParallel(); streamToJoin = streamToJoin.map(...).endParallel(); TStream<String> parallelStream = topology.source(...); parallelStream = parallelStream.parallel(4); parallelStream = parallelStream.union(streamToJoin); parallelStream.map(...).endParallel().print();
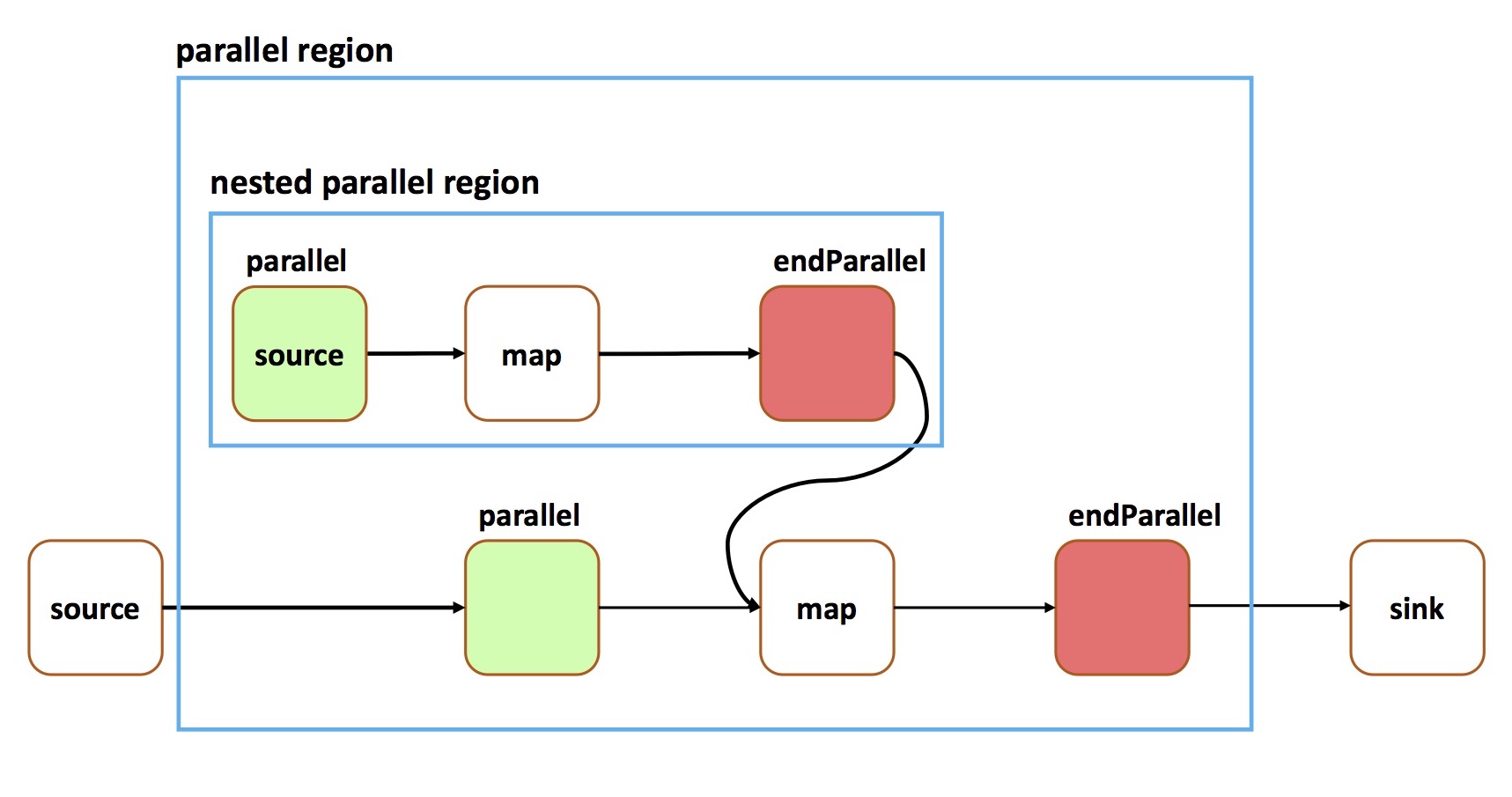
Limitations of parallel() are as follows:
Every call toendParallel()must have a call toparallel(...)preceding it. The following is invalid:
A parallelized stream cannot be joined with another window, and a parallelized window cannot be joined with a stream. The following is invalid:TStreammyStream = topology.strings("a","b","c"); myStream.endParallel(); TWindownumWindow = topology.strings("1","2","3").last(3); TStream stringStream = topology.strings("a","b","c"); TStream paraStringStream = myStream.parallel(5); TStream filtered = myStream.filter(...); filtered.join(numWindow, ...); - Parameters:
width- The degree of parallelism. seeparallel(int width)for more details.routing- Defines how tuples will be routed channels.- Returns:
- A reference to a TStream<> at the beginning of the parallel region.
- Throws:
java.lang.IllegalArgumentException- ifwidthis null- See Also:
Topology.createSubmissionParameter(String, Class),split(int, ToIntFunction)
- One stream invokes
-
parallel
TStream<T> parallel(Supplier<java.lang.Integer> width, Function<T,?> keyer)
Parallelizes the stream into a number of parallel channels using key based distribution.
For each tupletkeyer.apply(t)is called and then the tuples are routed so that all tuples with thesame key are sent to the same channel.- Parameters:
width- The degree of parallelism.keyer- Function to obtain the key from each tuple.- Returns:
- A reference to a stream with
widthchannels at the beginning of the parallel region. - See Also:
TStream.Routing.KEY_PARTITIONED,parallel(Supplier, Routing)
-
setParallel
TStream<T> setParallel(Supplier<java.lang.Integer> width)
Sets the current stream as the start of a parallel region.- Parameters:
width- The degree of parallelism.- Since:
- v1.9
- See Also:
parallel(int),parallel(Supplier, Routing),parallel(Supplier, Function)
-
endParallel
TStream<T> endParallel()
Ends a parallel region by merging the channels into a single stream.- Returns:
- A stream for which subsequent transformations are no longer parallelized.
- See Also:
parallel(int),parallel(Supplier, Routing),parallel(Supplier, Function)
-
sample
TStream<T> sample(double fraction)
Return a stream that is a random sample of this stream.- Parameters:
fraction- Fraction of the data to return.- Returns:
- Stream containing a random sample of this stream.
- Throws:
java.lang.IllegalArgumentException-fractionis less that or equal to zero or greater than 1.0.
-
isolate
TStream<T> isolate()
Return a stream whose immediate subsequent processing will execute in a separate operating system process from this stream's processing.
For the following Topology:
It is guaranteed that:-->transform1-->.isolate()-->transform2-->transform3-->.isolate()-->sinktransform1andtransform2will execute in separate processes.transform3andsinkwill execute in separate processes.
t1, t2, t3) are applied to a stream returned fromisolate()then it is guaranteed that each of them will execute in a separate operating system process to this stream, but no guarantees are made about wheret1, t2, t3are placed in relationship to each other.
Only applies for distributed contexts.- Returns:
- A stream that runs in a separate process from this stream.
-
lowLatency
TStream<T> lowLatency()
Return a stream that is guaranteed to run in the same process as the calling TStream. All streams that are created from the returned stream are also guaranteed to run in the same process untilendLowLatency()is called.
For example, for the following topology:
It is guaranteed that the filter and transform operations will run in the same process.---source---.lowLatency()---filter---transform---.endLowLatency()---
Only applies for distributed contexts.- Returns:
- A stream that is guaranteed to run in the same process as the calling stream.
-
endLowLatency
TStream<T> endLowLatency()
Return a TStream that is no longer guaranteed to run in the same process as the calling stream. For example, in the following topology:
It is guaranteed that the filter and transform operations will run in the same process, but it is not guaranteed that the transform and filter2 operations will run in the same process.---source---.lowLatency()---filter---transform---.endLowLatency()---filter2
Only applies for distributed contexts.- Returns:
- A stream that is not guaranteed to run in the same process as the calling stream.
-
throttle
TStream<T> throttle(long delay, java.util.concurrent.TimeUnit unit)
Throttle a stream by ensuring any tuple is submitted with leastdelayfrom the previous tuple.- Parameters:
delay- Maximum amount to delay a tuple.unit- Unit ofdelay.- Returns:
- Stream containing all tuples on this stream. but throttled.
-
asType
TStream<T> asType(java.lang.Class<T> tupleTypeClass)
Return a strongly typed reference to this stream. If this stream is already strongly typed as containing tuples of typetupleClassthenthisis returned.- Parameters:
tupleTypeClass- Class type for the tuples.- Returns:
- A stream with the same contents as this stream but strongly typed as
containing tuples of type
tupleClass.
-
autonomous
TStream<T> autonomous()
Return a stream matching this stream whose subsequent processing will execute in an autonomous region. By default IBM Streams processing is executed in an autonomous region where any checkpointing of operator state is autonomous (independent) of other operators.
This method may be used to end a consistent region by starting an autonomous region. This may be called even if this stream is in an autonomous region.
Autonomous is not applicable when a topology is submitted toembeddedandstandalonecontexts and will be ignored.- Since:
- v1.5
-
setConsistent
TStream<T> setConsistent(ConsistentRegionConfig config)
Set the operator that is the source of this stream to be the start of a consistent region to support at least once and exactly once processing. IBM Streams calculates the boundaries of the consistent region based on the reachability graph of this stream. A region can be bounded though use ofautonomous().Consistent regions are only supported in distributed contexts.
This must be called on a stream directly produced by an SPL operator that supports consistent regions. Source streams produced by methods on
Topologydo not support consistent regions.- Returns:
- this
- Since:
- 1.5 API added, 1.8 Working implementation.
- See Also:
ConsistentRegionConfig
-
output
com.ibm.streamsx.topology.builder.BOutput output()
Internal method.
Not intended to be called by applications, may be removed at any time.
-
connectTo
com.ibm.streamsx.topology.builder.BInputPort connectTo(com.ibm.streamsx.topology.builder.BOperatorInvocation receivingBop, boolean functional, com.ibm.streamsx.topology.builder.BInputPort input)Internal method.
Not intended to be called by applications, may be removed at any time.
Connect this stream to a downstream operator. If input is null then a new input port will be created, otherwise it will be used to connect to this stream. Returns input or the new port if input was null.
-
-