Kafka Toolkit > com.ibm.streamsx.kafka 3.2.2 > com.ibm.streamsx.kafka > KafkaConsumer
The KafkaConsumer operator is used to consume messages from Kafka topics. The operator can be configured to consume messages from one or more topics, as well as consume messages from specific partitions within topics.
The standard use patterns for the KafkaConsumer operator are described in the overview of the user documentation.
Supported Kafka Versions
This version of the toolkit supports Apache Kafka 0.10.2, 0.11, 1.0, 1.1, and all 2.x versions up to 2.7.
Using Kafka server version 0.10
- The consumer config isolation.level=read_uncommitted must be set. Otherwise the operator will fail with: org.apache.kafka.common.errors.UnsupportedVersionException: The broker does not support LIST_OFFSETS with version in range [2,5]. The supported range is [0,1]
- The staticGroupMember parameter cannot be set to true.
Kafka Properties
The operator implements Kafka's KafkaConsumer API of the Kafka client version 2.5.1. As a result, it supports all Kafka configurations that are supported by the underlying API. The consumer configs for the Kafka consumer 2.5 can be found in the Apache Kafka 2.5 documentation.
When you reference files within your application, which are bundled with the Streams application bundle, for example an SSL truststore or a key tab file for Kerberos authentication, you can use the {applicationDir} placeholder in the property values. Before the configs are passed to the Kafka client, the {applicationDir} placeholder is replaced by the application directory of the application. Examples how to use the placeholder are shown below.
ssl.truststore.location={applicationDir}/etc/myTruststore.jks
or
sasl.jaas.config=com.ibm.security.auth.module.Krb5LoginModule required \
debug=true \
credsType=both \
useKeytab="{applicationDir}/etc/myKeytab.keytab" \
principal="kafka-client@EXAMPLE.DOMAIN.COM";
The {applicationDir} placeholder can also be used to reference files that are configured as system properties, for example when you must specify the Kerberos client configuration, which is typically done for Linux servers system wide in /etc/krb5.conf.
In containerized environments and in cloud infrastructures, you cannot configure a system file, however. In such a scenario you want to bundle the Kerberos config file with your application and pass the file as a system property to the Java Virtual Machine using the vmArg operator parameter like this:
vmArg: "-Djava.security.krb5.conf={applicationDir}/etc/krb5.conf";
More about accessing a kerberized Kafka cluster can be found in the Kerberos chapter of the toolkit documentation.
Properties can be specified in a file or in an application configuration. If specifying properties via a file, the propertiesFile parameter can be used. If specifying properties in an application configuration, the name of the application configuration must be specified using the appConfigName parameter.
The only property that the user is required to set is the bootstrap.servers property, which points to the Kafka brokers, for example kafka-0.mydomain:9092,kafka-1.mydomain:9092,kafka-2.mydomain:9092. All other properties are optional.
The operator sets or adjusts some properties by default to enable users to quickly get started with the operator. The following lists which properties the operator sets by default:
|
Property Name |
Default Value |
|---|---|
|
auto.commit.enable |
adjusted to false |
|
client.id |
Generated ID in the form: C-J<JobId>-<operator name> when not user provided, when user provided and used in parallel region, the parallel channel number is added. |
|
group.id |
constructed from hashes of instance-ID, job-ID, and operator name |
|
group.instance.id |
when staticGroupMember parameter is true: hashes from instance-ID and operator name. When user provided and used in a parallel region, the parallel channel number is added. |
|
isolation.level |
read_committed |
|
key.deserializer |
See Automatic deserialization section below |
|
value.deserializer |
See Automatic deserialization section below |
|
partition.assignment.strategy |
When in consistent region, the partition assignment strategy is adjusted to strategies that support the EAGER protocol only. When not set or no EAGER only assignor remains, and in consistent region, org.apache.kafka.clients.consumer.RangeAssignor or org.apache.kafka.clients.consumer.RoundRobinAssignor is chosen dependent on number of subscribed topics. When not in a consistent region and no strategy is given: org.apache.kafka.clients.consumer.RoundRobinAssignor when multiple topics or a pattern is subscribed. Otherwise Kafka's built-in default applies. |
|
max.poll.interval.ms |
adjusted to a minimum of 3 * max (reset timeout, drain timeout) when in consistent region, 300000 otherwise |
|
metadata.max.age.ms |
adjusted to a maximum of 2000 |
|
session.timeout.ms |
when unset, set to max (1.2 * reset timeout, 120000) when the operator is a static consumer group member, to 20000 otherwise |
|
request.timeout.ms |
adjusted to 25000 when the operator is a static consumer group member, to session.timeout.ms + 5000 otherwise |
|
metric.reporters |
added to provided reporters: com.ibm.streamsx.kafka.clients.consumer.ConsumerMetricsReporter |
|
metrics.sample.window.ms |
adjusted to 10000 |
|
client.dns.lookup |
use_all_dns_ips |
|
reconnect.backoff.max.ms |
10000 |
|
reconnect.backoff.ms |
250 |
|
retry.backoff.ms |
500 |
NOTE: Although properties are adjusted, users can override any of the above properties by explicitly setting the property value in either a properties file or in an application configuration.
Automatic Deserialization
The operator will automatically select the appropriate deserializers for the key and message based on their types. The following table outlines which deserializer will be used given a particular type:
|
Deserializer |
SPL Types |
|---|---|
|
org.apache.kafka.common.serialization.StringDeserializer |
rstring |
|
org.apache.kafka.common.serialization.IntegerDeserializer |
int32, uint32 |
|
org.apache.kafka.common.serialization.LongDeserializer |
int64, uint64 |
|
org.apache.kafka.common.serialization.FloatDeserializer |
float32 |
|
org.apache.kafka.common.serialization.DoubleDeserializer |
float64 |
|
org.apache.kafka.common.serialization.ByteArrayDeserializer |
blob |
These deserializers are wrapped by extensions that catch exceptions of type org.apache.kafka.common.errors.SerializationException to allow the operator to skip over malformed messages. The used extensions do not modify the actual deserialization function of the given base deserializers from the above table.
Users can override this behavior and specify which deserializer to use by setting the key.deserializer and value.deserializer properties.
Following metrics created by the Kafka consumer client are exposed as custom metrics:
|
Custom Metric |
Description |
|---|---|
|
connection-count |
The current number of active connections. |
|
incoming-byte-rate |
The number of bytes read off all sockets per second |
|
topic-partition:records-lag |
The latest lag of the specific partition. A value of -1 indicates that the metric is not applicable to the operator. |
|
records-lag-max |
The maximum lag in terms of number of records for any partition in this window |
|
fetch-size-avg |
The average number of bytes fetched per request |
|
topic:fetch-size-avg |
The average number of bytes fetched per request for a topic |
|
commit-rate |
The number of commit calls per second |
|
commit-latency-avg |
The average time taken for a commit request |
Committing received Kafka messages
Committing offsets is always controlled by the Streams operator. All auto-commit related settings via consumer properties are ignored by the operator.
a) The operator is not part of a consistent region
The consumer operator commits the offsets of those Kafka messages, which have been submitted as tuples. Offsets are committed under the following conditions:
1. The partitions within a consumer group are rebalanced. Before new partitions are assigned, the offsets of the currently assigned partitions are committed. When the partitions are re-assigned, the operators start fetching from these committed offsets. The periodic commit controlled by the commitCount or commitPeriod parameter is reset after rebalance. A partition rebalance happens every time a subscription via control port is changed.
2. Offsets are committed periodically. The period can be a time period or a tuple count. If nothing is specified, offsets are committed every 5 seconds. The time period can be specified with the commitPeriod parameter. When the commitCount parameter is used with a value of N, offsets are committed every N submitted tuples.
3. Partition assignment or subscription via control port is removed. The offsets of those partitions which are de-assigned are committed.
b) The operator is part of a consistent region
Offsets are always committed when the consistent region drains, i.e. when the region becomes a consistent state. On drain, the consumer operator commits the offsets of those Kafka messages that have been submitted as tuples. When the operator is in a consistent region, the parameters commitCount and commitPeriod are ignored because the commit frequency is given by the trigger period of the consistent region. In a consistent region, offsets are committed synchronously, i.e. the offsets are committed when the drain processing of the operator finishes. Commit failures result in consistent region reset.
Kafka's Group Management
The operator is capable of taking advantage of Kafka's group management function. 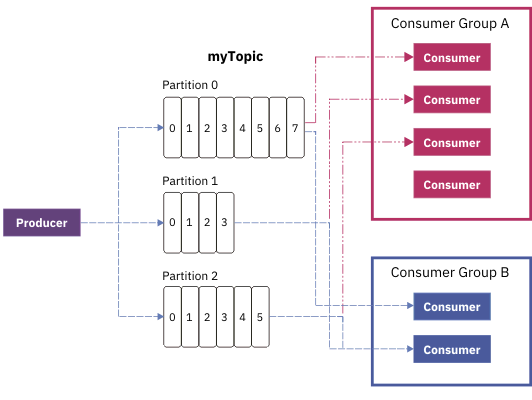
In the figure above, the topic myTopic with three partitions is consumed by two consumer groups. In Group A, which has four consumers, one consumer is idle because the number of partitions is only three. All other consumers in the group would consume exactly one topic partition. Consumer group B has less consumers than partitions. One consumer is assigned to two partitions. The assignment of consumers to partition(s) is fully controlled by Kafka.
In order for the operator to use this function, the following requirements must be met
- A group.id consumer property must be given when multiple consumer operators need to participate in the consumer group. The group-ID defines which operators belong to a consumer group. When no group-ID is given, the operator will create a unique group identifier and will be a single group member. The group.id can be specified via property file, app configuration, or the groupId parameter.
- When in a consistent region, the operator must not be configured with the optional input port.
- The partition parameter must not be used.
- when the operator is in a consistent region and is configured with the optional input port, or
- when the partition parameter is specified.
In a consistent region, a consumer group must not have consumers outside of the consistent region, for example in a different Streams job.
When not in a consistent region, the consumer group must not have consumers outside of the Streams job unless the startPosition parameter is not used or has the value Default.
When group management is used together with startPosition Beginning, End, or Time, the application graph must have a JobControlPlane operator to work correctly. When the JobControlPlane operator cannot be connected, the operator will fail to initialize.
Metrics related to group management
|
metric name |
description |
|---|---|
|
isGroupManagementActive |
1 indicates that group management is active, 0 indicates that group management is inactive. |
|
nPartitionRebalances |
Number of partition assignment rebalances for each consumer operator. The metric is only visible when group management is active. |
Static Consumer Group Membership
To benefit from this feature, the Kafka server must be at minimum version 2.3.
Since version 2.3, Kafka supports static group membership, more detailed in this confluent blog post.
Streams applications can benefit from this feature as it avoids unnecessary consumer group rebalances when PEs are re-launched. With dynamic group members (the traditional behavior), a consumer actively leaves the group when its PE is re-launched, leading to an immediate partition rebalance among the remaining consumers.
With static group membership, a consumer leaves the group only based on the session timeout, i.e. when the broker does not receive the heartbeat from the consumer for longer than the session timeout. When the session timeout is high enough, the remaining consumers in a consumer group within an autonomous region will not be affected from the restart of another consumer. They will continue consuming the assigned partitions without being re-assigned to partitions and reset to their last committed offsets. A consumer group within a consistent region benefits also when unnecessary rebalances are avoided because a rebalance always triggers a reset of the consistent region. That's why this feature can help avoid unnecessary consistent region resets.
You can enable this feature by setting either the consumer config group.instance.id to a unique value within the consumer group, or by setting the staticGroupMember parameter to true, which creates a uniqe group.instance.id. When a group.instance.id is detected, the operator automatically increases the default session timeout when no user-provided session timeout is given.
Incremental Cooperative Rebalancing of Consumer Groups
Kafka 2.4 implemented incremental cooperative rebalancing of consumers, KIP-429. The rebalancing protocol is an embedded protocol between the consumer that is chosen as the group leader, and the other group members to negotiate who owns which partitions. The Kafka server, especially the group coordinator is not aware of this embedded protocol, so that the new rebalancing protocol is available for all Kafka server versions, which are supported by this toolkit.
The new rebalancing strategy is beneficial for large consumer groups and happens in multiple rounds, in which only some topic partitions are moved (revoked/assigned) between consumers. Partitions that need not be revoked, stay assigned and continue being consumed. A more elaborated description of this new feature can be found in this confluent blog post.
Activation
Use following consumer property for all consumers within the consumer group: partition.assignment.strategy=org.apache.kafka.clients.consumer.CooperativeStickyAssignor
- org.apache.kafka.clients.consumer.RangeAssignor
- org.apache.kafka.clients.consumer.RoundRobinAssignor
- org.apache.kafka.clients.consumer.StickyAssignor
Note: When the consumer operator is used in a consistent region, automatically an assignor for the EAGER protocol is configured as every rebalance iteration would trigger a reset of the consistent region. The reset of a consistent region is a stop-the-world event for the application so that consumers in a consistent region would not benefit from incremental rebalancing. On the contrary, incremental rebalancing could have a negative impact in consistent region.
Checkpointing behavior in an autonomous region
The operator can be configured for operator driven and periodic checkpointing. Checkpointing is in effect when the operator is configured with an input port. When the operator has no input port, checkpointing can be configured, but is silently ignored. The operator checkpoints the current partition assignment or topic subscription, which is modified via control tuples received by the input port. The current fetch positions are not saved.
On reset, the partition assignment or topic subscription is restored from the checkpoint. The fetch offsets will be the last committed offsets.
With config checkpoint: operatorDriven; the operator creates a checkpoint when the manual partition assignment or the topic subscription changed, i.e. after each input tuple has been processed, which changed the assignment or subscription of the operator.
Operator restart behavior
When in a consistent region
When the operator is part of a consistent region, the operator is reset to the initial state or to the last consistent state when the PE is re-launched. The operator or the group of consumer operators replay tuples. There are no specifics in this case.
When not in a consistent region
a) The consumer operator has no input port
With group management enabled, the operators of a consumer group need a JobControlPlane operator in the application graph to coordinate the initial fetch offsets when the startPosition parameter is set and not Default. When re-launched, the operator seeks a partition to the fetch offset given by startPosition when none of the operators within the group previously committed offsets for this partition. When offsets have been committed, the fetch offset for a partition at operator start will be its last committed offset. This behavior enables you to change the width of a parallel region with consumers being a consumer group. The JobControlPlane operator is not required when the startPosition parameter is not used or has the value Default.
When group management is not enabled for a consumer operator (no group identifier specified or partitions specified), i.e. a single consumer is pinned to topic partitions, a JobControlPlane operator is required in the application graph when startPosition is not Default. The consumer operator stores those partitions in it for which it has already committed offsets. These partitions will not be seeked to startPosition after re-launch of a PE.
Omitting the startPosition parameter or using Default as the value does not require a JobControlPlane operator.
b) The consumer operator is configured with a control input port
When the operator is configured with an input port, the partition assignments or subscription, which have been created via the control stream, are lost. It is therefore recommended to fuse the consumer operator with the source of the control stream to replay the control tuples after restart or to use a config checkpoint clause, preferably operatorDriven, to restore the partition assignment and continue fetching records beginning with the last committed offsets.
Consistent Region Support
The operator can be the start of a consistent region. Both operator driven and periodic triggering of the region are supported. If using operator driven, the triggerCount parameter must be set to indicate how often the operator should initiate a consistent region.
Unless the operator is configured with an input port or the partition parameter is used, the operator participates automatically in a consumer group defined by a user provided or operator generated group ID. A consistent region can have multiple consumer groups.
Tuple replay after reset of the consistent region
After reset of the consistent region, the operators that participate in a consumer group may replay tuples that have been submitted by a different consumer before. The reason for this is, that the assignment of partitions to consumers can change. This property of a consumer group must be kept in mind when combining consumer groups with consistent region.
When the partition parameter is used or the operator has an input port, the partition assignment is static (a consumer consumes all partitions or those, which are specified), so that the consumer operator replays after consistent region reset those tuples, which it has submitted before.
When the consumers of a consumer group rebalance the partition assignment, for example, immediately after job submission, or when the broker node being the group's coordinator is shutdown, multiple resets of the consistent region can occur when the consumers start up. It is recommended to set the maxConsecutiveResetAttempts parameter of the @consistent annotation to a higher value than the default value of 5.
On drain, the operator will commit offsets of the submitted tuples.
On checkpoint, the operator will save the last offset for each topic-partition that it is assigned to. In the event of a reset, the operator will seek to the saved offset for each topic-partition and begin consuming messages from that point.
Metrics related to consistent region
|
metric name |
description |
|---|---|
|
drainTimeMillis |
drain duration of the last drain in milliseconds |
|
drainTimeMillisMax |
maximum drain duration in milliseconds |
These metrics are only present when the operator participates in a consistent region.
Error Handling
Many exceptions thrown by the underlying Kafka API are considered fatal. In the event that Kafka throws an exception, the operator will restart.
Summary
- Ports
- This operator has 1 input port and 1 output port.
- Windowing
- This operator does not accept any windowing configurations.
- Parameters
- This operator supports 24 parameters.
Optional: appConfigName, clientId, commitCount, commitPeriod, groupId, krb5Debug, outputKeyAttributeName, outputMessageAttributeName, outputOffsetAttributeName, outputPartitionAttributeName, outputTimestampAttributeName, outputTopicAttributeName, partition, pattern, propertiesFile, sslDebug, startOffset, startPosition, startPositionStr, startTime, staticGroupMember, topic, triggerCount, userLib
- Metrics
- This operator reports 8 metrics.
Properties
- Implementation
- Java
- Ports (0)
-
This port is used to specify the topics or topic partitions that the consumer should begin reading messages from. When this port is specified, the topic, partition and startPosition parameters cannot be used. The operator will only begin consuming messages once a tuple is received on this port, which specifies a partition assignment or a topic subscription.
When the KafkaConsumer participates in a consistent region, only partition assignment via control port is supported. The support of consistent region with the control port is deprecated and may be removed in next major toolkit version.
When a topic subscription is specified, the operator benefits from Kafka's group management (Kafka assigns the partitions to consume). When an assignment is specified in a control tuple, the operator self-assigns to the given partition(s). Assignments and subscriptions via control port cannot be mixed. Note, that it is not possible to use both assignment and subscription, it is also not possible to subscribe after a previous assignment and unassignment, and vice versa. This input port must contain a single rstring attribute that takes a JSON formatted string.
Adding or removing a topic subscription
To add or remove a topic subscription, the single rstring attribute must contain a JSON string in the following format:
{ "action" : "ADD" or "REMOVE", "topics" : [ { "topic" : "topic-name" }, ... ] }The following types and convenience functions are available to aid in creating the JSON string:
- rstring createMessageAddTopic (rstring topic);
- rstring createMessageAddTopics (list<rstring> topics);
- rstring createMessageRemoveTopic (rstring topic)
- rstring createMessageRemoveTopics (list<rstring> topics);
Adding or removing a manual partition assignment
To add or remove a topic partition assignment, the single rstring attribute must contain a JSON string in the following format:
{ "action" : "ADD" or "REMOVE", "topicPartitionOffsets" : [ { "topic" : "topic-name" ,"partition" : <partition_number> ,"offset" : <offset_number> <--- the offset attribute is optional }, ... ] }The offset element is optional. It specifies the offset of the first record to consume from the topic partition. This works as follows:- To seek to the beginning of a topic-partition, set the value of the offset to -2.
- To seek to the end of a topic-partition, set the value of the offset attribute to -1.
- To start fetching from the default position, omit the offset attribute or set the value of the offset to -3
- Any other value will cause the operator to seek to that offset value. If that value does not exist, then the operator will use the auto.offset.reset policy to determine where to begin reading messages from.
The following types and convenience functions are available to aid in creating the JSON string:
- type Control.TopicPartition = rstring topic, int32 partition;
- type Control.TopicPartitionOffset = rstring topic, int32 partition, int64 offset;
- rstring createMessageRemoveTopicPartition (rstring topic, int32 partition);
- rstring createMessageAddTopicPartition (rstring topic, int32 partition, int64 offset);
- rstring createMessageAddTopicPartition (list<Control.TopicPartitionOffset> topicPartitionsToAdd);
- rstring createMessageAddTopicPartition (list<Control.TopicPartition> topicPartitionsToAdd);
- rstring createMessageRemoveTopicPartition (rstring topic, int32 partition);
- rstring createMessageRemoveTopicPartition (list<Control.TopicPartition> topicPartitionsToRemove);
Important Note: This input port must not receive a final punctuation. Final markers are automatically forwarded causing downstream operators close their input ports. When this input port receives a final marker, it will stop fetching Kafka messages and stop submitting tuples.
- Properties
-
- Optional: true
- ControlPort: true
- WindowingMode: NonWindowed
- WindowPunctuationInputMode: Oblivious
- Assignments
- Java operators do not support output assignments.
- Ports (0)
-
This port produces tuples based on records read from the Kafka topic(s). A tuple will be output for each record read from the Kafka topic(s).
- Properties
-
- Optional: false
Optional: appConfigName, clientId, commitCount, commitPeriod, groupId, krb5Debug, outputKeyAttributeName, outputMessageAttributeName, outputOffsetAttributeName, outputPartitionAttributeName, outputTimestampAttributeName, outputTopicAttributeName, partition, pattern, propertiesFile, sslDebug, startOffset, startPosition, startPositionStr, startTime, staticGroupMember, topic, triggerCount, userLib
- appConfigName
-
Specifies the name of the application configuration containing Kafka properties.
- Properties
-
- Type: rstring
- Cardinality: 1
- Optional: true
- clientId
-
Specifies the client ID that should be used when connecting to the Kafka cluster. The value specified by this parameter will override the client.id Kafka property if specified.
Each operator must have a unique client ID. When operators are replicated by a parallel region, the channel-ID is automatically appended to the clientId to make the client-ID distinct for the parallel channels.
If this parameter is not specified and the client.id Kafka property is not specified, the operator will create an ID with the pattern C-J<job-ID>-<operator name> for a consumer operator, and P-J<job-ID>-<operator name> for a producer operator.
- Properties
-
- Type: rstring
- Cardinality: 1
- Optional: true
- commitCount
-
This parameter specifies the number of tuples that will be submitted to the output port before committing their offsets. Valid values are greater than zero. This parameter is optional and conflicts with the commitPeriod parameter.
This parameter is only used when the operator is not part of a consistent region. When the operator participates in a consistent region, offsets are always committed when the region drains.
- Properties
-
- Type: int32
- Cardinality: 1
- Optional: true
- commitPeriod
-
This parameter specifies the period of time in seconds, after which the offsets of submitted tuples are committed. This parameter is optional and has a default value of 5.0. Its minimum value is 0.1, smaller values are pinned to 0.1 seconds. This parameter cannot be used when the commitCount parameter is used.
This parameter is only used when the operator is not part of a consistent region. When the operator participates in a consistent region, offsets are always committed when the region drains.
- Properties
-
- Type: float64
- Cardinality: 1
- Optional: true
- groupId
-
Specifies the group ID that should be used when connecting to the Kafka cluster. The value specified by this parameter will override the group.id Kafka property if specified. If this parameter is not specified and the group.id Kafka property is not specified, the operator will use a generated group ID, and be a single group member unless the partition parameter is used.
- Properties
-
- Type: rstring
- Cardinality: 1
- Optional: true
- krb5Debug
-
If Kerberos debugging is enabled, all Kerberos related protocol data and information is logged to the console. This setting is equivalent to vmArg: "-Dcom.ibm.security.krb5.Krb5Debug=all";. The default value for this parameter is false. The parameter is ignored when the com.ibm.security.krb5.Krb5Debug property is set via the vmArg parameter.
- Properties
-
- Type: boolean
- Cardinality: 1
- Optional: true
- outputKeyAttributeName
-
Specifies the output attribute name that should contain the key. If not specified, the operator will attempt to store the message in an attribute named 'key'.
- Properties
-
- Type: rstring
- Cardinality: 1
- Optional: true
- outputMessageAttributeName
-
Specifies the output attribute name that will contain the message. If not specified, the operator will attempt to store the message in an attribute named 'message'.
- Properties
-
- Type: rstring
- Cardinality: 1
- Optional: true
- outputOffsetAttributeName
-
Specifies the output attribute name that should contain the offset. If not specified, the operator will attempt to store the message in an attribute named 'offset'. The attribute must have the SPL type 'int64' or 'uint64'.
- Properties
-
- Type: rstring
- Cardinality: 1
- Optional: true
- outputPartitionAttributeName
-
Specifies the output attribute name that should contain the partition number. If not specified, the operator will attempt to store the partition number in an attribute named 'partition'. The attribute must have the SPL type 'int32' or 'uint32'.
- Properties
-
- Type: rstring
- Cardinality: 1
- Optional: true
- outputTimestampAttributeName
-
Specifies the output attribute name that should contain the record's timestamp. It is presented in milliseconds since Unix epoch.If not specified, the operator will attempt to store the message in an attribute named 'messageTimestamp'. The attribute must have the SPL type 'int64' or 'uint64'.
- Properties
-
- Type: rstring
- Cardinality: 1
- Optional: true
- outputTopicAttributeName
-
Specifies the output attribute name that should contain the topic. If not specified, the operator will attempt to store the message in an attribute named 'topic'.
- Properties
-
- Type: rstring
- Cardinality: 1
- Optional: true
- partition
-
Specifies the partitions that the consumer should be assigned to for each of the topics specified. When you specify multiple topics, the consumer reads from the given partitions of all given topics. For example, if the topic parameter has the values "topic1", "topic2", and the partition parameter has the values 0, 1, then the consumer will assign to {topic1, partition 0}, {topic1, partition 1}, {topic2, partition 0}, and {topic2, partition 1}.
Notes:- Partiton numbers in Kafka are zero-based. For example, a topic with three partitions has the partition numbers 0, 1, and 2.
- When using this parameter, the consumer will assign the consumer to the specified topics partitions, rather than subscribe to the topics. This implies that the consumer will not use Kafka's group management feature.
- This parameter is incompatible with the optional input port.
- pattern
-
Specifies a regular expression to subscribe dynamically all matching topics. The pattern matching will be done periodically against topic existing at the time of check.
Some basic examples:- pattern: "myTopic"; subscribes only to topic myTopic when it is present.
- pattern: "myTopic.*"; subscribes to myTopic and all topics that begin with myTopic
- pattern: ".*Topic"; subscribes to Topic and all topics that end at Topic
This parameter is incompatible with the topic and the partition parameters, and with the optional input port.
The regular expression syntax follows the Perl 5 regular expressions with some differences. For details see Regular Expressions in Java 8.
- Properties
-
- Type: rstring
- Cardinality: 1
- Optional: true
- propertiesFile
-
Specifies the name of the properties file containing Kafka properties. A relative path is always interpreted as relative to the application directory of the Streams application.
- Properties
-
- Type: rstring
- Cardinality: 1
- Optional: true
- sslDebug
-
If SSL/TLS protocol debugging is enabled, all SSL protocol data and information is logged to the console. This setting is equivalent to vmArg: "-Djavax.net.debug=true";. The default value for this parameter is false. The parameter is ignored when the javax.net.debug property is set via the vmArg parameter.
- Properties
-
- Type: boolean
- Cardinality: 1
- Optional: true
- startOffset
-
This parameter indicates the start offset that the operator should begin consuming messages from. In order for this parameter's values to take affect, the startPosition parameter must be set to Offset. Furthermore, the specific partition(s) that the operator should consume from must be specified via the partition parameter.
If multiple partitions are specified via the partition parameter, then the same number of offset values must be specified. There is a one-to-one mapping between the position of the partition from the partition parameter and the position of the offset from the startOffset parameter. For example, if the partition parameter has the values 0, 1, and the startOffset parameter has the values 100l, 200l, then the operator will begin consuming messages from partition 0 at offset 100 and will consume messages from partition 1 at offset 200.
A limitation with using this parameter is that only one single topic can be specified via the topic parameter.
- startPosition
-
Specifies where the operator should start reading from topics. Valid options include: Beginning, End, Default, Time, and Offset.
- Beginning: The consumer starts reading from the beginning of the data in the Kafka topics. It starts with smallest available offset.
- End: The consumer starts reading at the end of the topic. It consumes only newly inserted data.
- Default: Kafka decides where to start reading. When the consumer has a group ID that is already known to the Kafka broker, the consumer starts reading the topic partitions from where it left off (after last committed offset). When the consumer has an unknown group ID, consumption starts at the position defined by the consumer config auto.offset.reset, which defaults to latest. Consumer offsets are retained for the time specified by the broker config offsets.retention.minutes, which defaults to 1440 (24 hours). When this time expires, the Consumer won't be able to resume after last committed offset, and the value of consumer property auto.offset.reset applies (default latest).
- Time: The consumer starts consuming messages with at a given timestamp. More precisely, when a time is specified, the consumer starts at the earliest offset whose timestamp is greater than or equal to the given timestamp. If no consumer offset is found for a given timestamp, the consumer starts consuming from what is configured by consumer config auto.offset.reset, which defaults to latest. The timestamp where to start consuming must be given as startTime parameter in milliseconds since Unix epoch.
- Offset: The consumer starts consuming at a specific offset. The offsets must be specified for all topic partitions by using the startOffset parameter. This implies that the partition parameter must be specified and that Kafka's group management feature cannot be used as the operator assigns itself statically to the given partition(s). When Offset is used as the start position only one single topic can be specified via the topic parameter, and the operator cannot participate in a consumer group.
If this parameter is not specified, the start position is Default. This parameter is incompatible with the optional input port.
Note, that using a startPosition other than Default requires the application always to have a JobControlPlane operator in its graph. The startPosition is effective only when the Consumer has not yet committed offsets during the Streams job's life cycle.
When you need to specify the start position as an rstring type expression, for example when you want to use a submission time value as start position, use the startPositionStr parameter instead. This parameter is incompatible with the startPositionStr parameter. Specify only one of them.
- Properties
-
- Type: com.ibm.streamsx.kafka.clients.consumer.StartPosition (Beginning, End, Default, Time, Offset)
- Cardinality: 1
- Optional: true
- ExpressionMode: CustomLiteral
- startPositionStr
-
Specifies where the operator should start reading from topics. Use this parameter when you need to specify the start position as an rstring expression, for example when you want to use a submission time value as start position.
The supported values, conditions, and restrictions are the same as for the startPosition parameter.
This parameter is incompatible with the startPosition parameter. Specify only one of them.
- Properties
-
- Type: rstring
- Cardinality: 1
- Optional: true
- startTime
-
This parameter is only used when the startPosition parameter is set to Time. Then the operator will begin reading records from the earliest offset whose timestamp is greater than or equal to the timestamp specified by this parameter. If no offsets are found, then the operator will begin reading messages from what is is specified by the auto.offset.reset consumer property, which is latest as default value. The timestamp must be given as an 'int64' type in milliseconds since Unix epoch.
- Properties
-
- Type: int64
- Cardinality: 1
- Optional: true
- staticGroupMember
-
Enables static Kafka group membership (generates and sets a group.instance.id overriding a potentially user provided group instance identifier) and sets a higher default session timeout. when set to true.
This parameter is ignored when group management is not active.
Please note, that the Kafka server version must be at minimum 2.3 to use static group membership. With lower version, the operator will fail.
The default value of this parameter is false.
- Properties
-
- Type: boolean
- Cardinality: 1
- Optional: true
- topic
-
Specifies the topic or topics that the consumer should subscribe to. To assign the consumer to specific partitions, use the partitions parameter in addition. To specify multiple topics from which the operator should consume, separate the topic names by comma, for example topic: "topic1", "topic2";, or topic: "topic1,topic2";. The second form can also be used to provide multiple topics from a submission time parameter. To subscribe to multiple topics that match a regular expression, use the pattern parameter.
This parameter is incompatible with the optional input port.
- triggerCount
-
This parameter specifies the number of tuples that will be submitted to the output port before triggering a consistent region. This parameter is only used if the operator is the start of an operator driven consistent region and is ignored otherwise.
- Properties
-
- Type: int32
- Cardinality: 1
- Optional: true
- userLib
-
Allows the user to specify paths to JAR files that should be loaded into the operators classpath. This is useful if the user wants to be able to specify their own partitioners or assignors. The value of this parameter can either point to a specific JAR file, or to a directory. In the case of a directory, the operator will load all files ending in .jar onto the classpath. By default, this parameter will load all jar files found in <application_dir>/etc/libs.
- isGroupManagementActive - Gauge
-
Shows the Kafka group management state of the operator. When the metric shows 1, group management is active. When the metric is 0, group management is not in place.
- nAssignedPartitions - Gauge
-
Number of topic partitions assigned to the consumer.
- nConsumedTopics - Gauge
-
Number of topics consumed by this consumer. This is the number of topics of the assigned partitions. Note, that a consumer can subscribe to topics, or to a pattern matching numerous topics, but cannot have assigned partitions of the subscribed topics. This metric value is never higher than metric nAssignedPartitions.
- nDroppedMalformedMessages - Counter
-
Number of dropped malformed messages
- nFailedControlTuples - Counter
-
Number of failed tuples received on control port
- nLowMemoryPause - Counter
-
Number times message fetching was paused due to low memory.
- nPendingMessages - Gauge
-
Number of pending messages to be submitted as tuples.
- nQueueFullPause - Counter
-
Number times message fetching was paused due to full queue.
- Operator class library
- Library Path: ../../impl/java/bin, ../../opt/downloaded/*, ../../impl/lib/*