Toolkit technical background overview
The Adaptive Parser project contains a set of toolkits that aims to parse structured, semi-structured and most notably unstructured data streams. It’s capable of parsing hierarchical data structures and supports customizing the parser’s behavior on any attribute level. It includes the AdaptiveParser operator in the base toolkit and other toolkits for parsing other data formats, including:
- Bro log format
- CEF format
- CLF format
- JSON format
- LEEF format
This article will cover the first steps of starting out with the AdaptiveParser operator. It is assumed that the reader has already basic knowledge of developing IBM Streams applications. If you are not familiar with Streams, learn more using the Quick Start Guide.
When should you use the Adaptive Parser toolkit?
The Adaptive Parser toolkit has been built from the ground up to provide a fully optimal solution for parsing data. The toolkit enables to handle the parsing stage as a first class citizen within a stream while being totally decoupled from the ingest part. Once the parse stage has been unplugged from the ingestion, ?smarter? parsing techniques can be applied (like automatic parser generation from a given tuple). Why is this so important?
In most IBM Streams related projects the developer has to achieve three main goals when handling an input:
- Ingest data from various sources (such as files, cloud, network data, sensors)
- Parse the the data being ingested based on schema requirements
- Transform the data into a friendlier format to make further processing
Some of these steps might be combined into a single step, for example, the FileSource operator both ingests data from a file and parses it depending on the indicated format. Combining these steps is usually the right choice for demos and pilots, but a best practice is to manage these three tasks separately.
When separating parsing from ingest steps we gain the following value adds:
- The “parsing” stage becomes “data source agnostic”, since it’s not tightly coupled with the “ingest” part
- Various optimizations can be applied (such as co-location, placement, parallelism)
- The parser is chosen because its “best tool for the job” and not limited by the ingestion capabilities to parse
- Single framework for all parsing requirements
This article will show how to use the AdaptiveParser operator for:
- Basic parsing of streaming data
- Parsing streaming data with a delimiter
- Parsing streaming data with a skipper
- Parsing streaming data combining a delimiter with a skipper
Basic parsing of streaming data
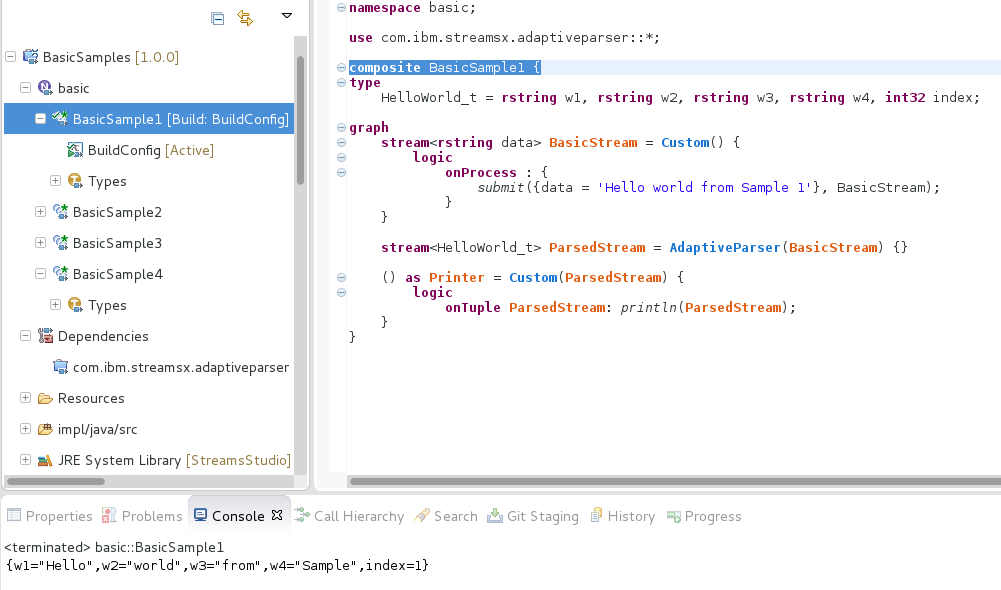
The following example shows how to use AdaptiveParser operator in its most simplistic form - by default it uses white space as its delimiter.
In the next sections we will provide more details about configuring various delimiters and skippers.
This first example shows the parser without any parameters:
Parsing streaming data with a global delimiter
The following example shows parsing with AdaptiveParser operator using a delimiter to separate between values.
What does the “global” stand for?
In the next articles we will further explain this feature, but to give a little taste: the feature is called “global” in order to support hierarchical structures with directive inheritance support (e.g. JSON format).
The global delimiter should be of type “rstring”, let’s take a closer look at the next example:
stream<parsed_type> ParsedStream = AdaptiveParser(BasicStream) {
param
globalDelimiter: ",";
}
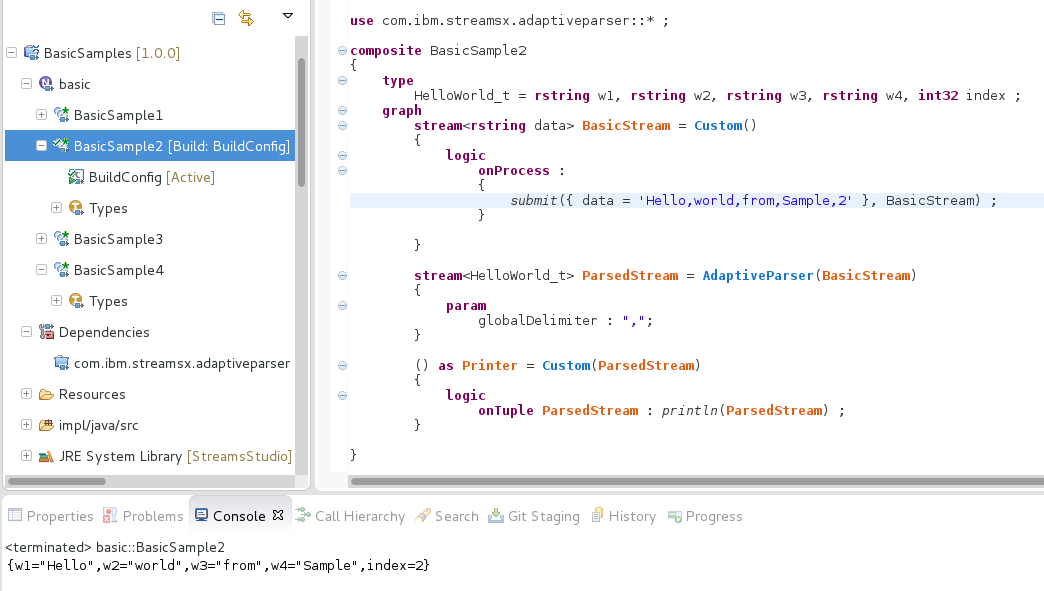
The example above demonstrates parsing of comma separated values by a delimiter directive.
Parsing streaming data with a global skipper
The following example shows parsing with AdaptiveParser operator using a skipper to separate between values.
The global skipper should be one of the following types:
- none: skipper is disabled - all input characters are parsed as values
- blank: skips spaces and tabs
- control: skip control characters
- endl: skip new lines
- punct: skip punctuation symbols
- tab: skip tabs
- whitespace: skip all whitespaces (default)
Let’s take a closer look at the next example:
stream<parsed_type> ParsedStream = AdaptiveParser(BasicStream) {
param
globalSkipper : tab;
}
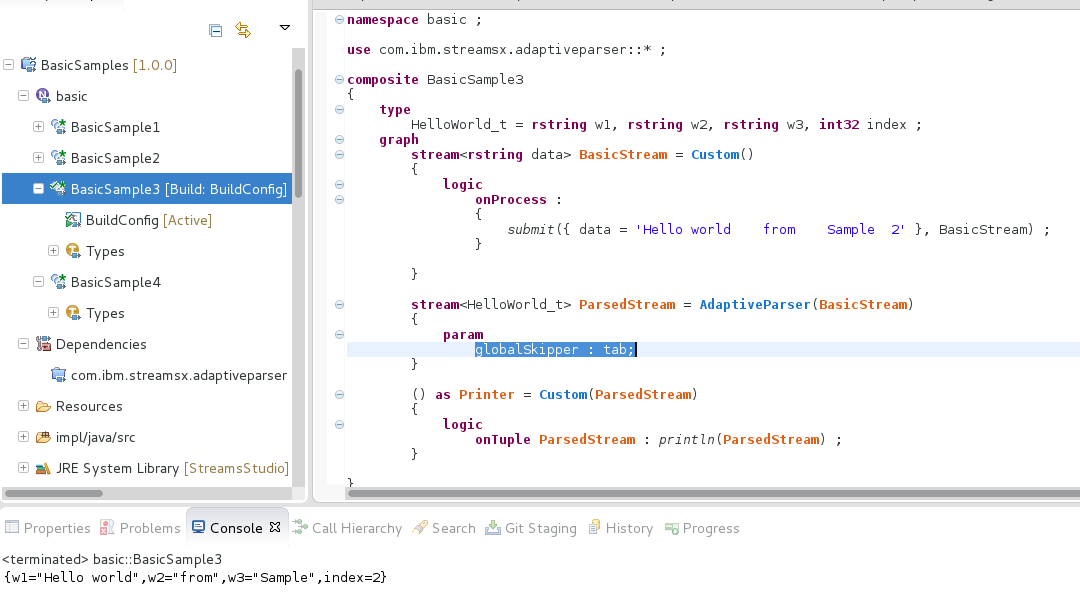
The example above demonstrates parsing of “tab” separated values by a skipper directive (which means other white-spaces are valid and therefore will not be skipped). Take note of the fact that “Hello world” was parsed as a single value.
Putting it all together
stream<parsed_type> ParsedStream = AdaptiveParser(BasicStream) {
param
globalDelimiter : "," ;
globalSkipper : blank; // means tabs and spaces are both skipped
}
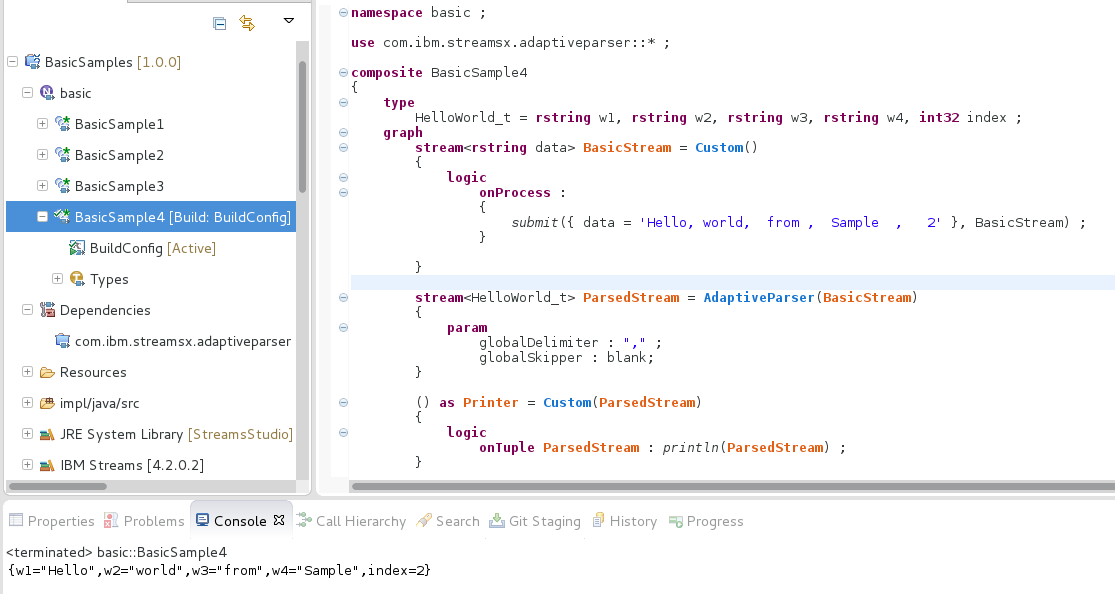
The example above demonstrates a typical use case of parsing data formatted with comma separated values (“CSV”).
Take note of the fact that in this case a skipper only complements the delimiter functionality by skipping unwanted white-space characters.