Module 10 - Table format output
Edit meObjectives
In this module, you extend the ITE application that you created in the modules 1-8.
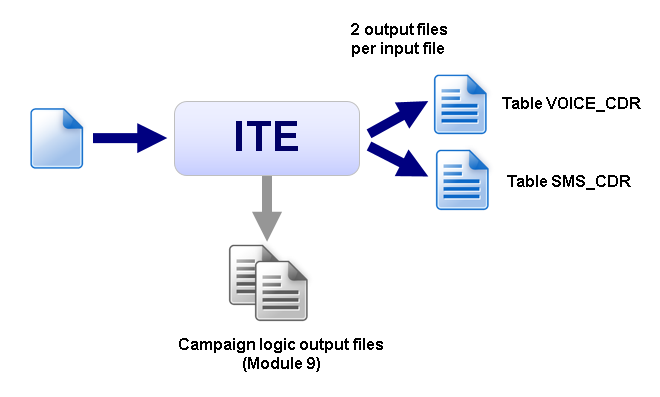
At the end of this module, your application creates two types of output files, which can be loaded into database tables.
After completing this module you should be able to:
- Configure the ITE application for table files output
- Customize the PostContextDataProcessor composite
Prerequisites
You finished at least module 8 of the tutorial, in which you added the record deduplication.
Concepts
Imagine, you have the project requirement to split the CDRs according to the record type into two tables:
- The table VOICE_CDR contains all records with cdrRecordType 1
- The table SMS_CDR contains all other records
For the CDR repository, two database tables are the final destinations. The ITE application does not write directly into the database but generates output files, which can be loaded into the database by a separate running DbLoader application. So the output files need to have a format corresponding to the tables. These file formats are a CSV format with correct column type and order as defined in the database tables. The table format definitions are available in file production.ddl.
Customization Points
The following figure and table show the points that you need to customize in the ITE application during this module or that influence the customization like the different formats and stream schemes. Other parts don’t need to be customized because it is not necessary for this module.
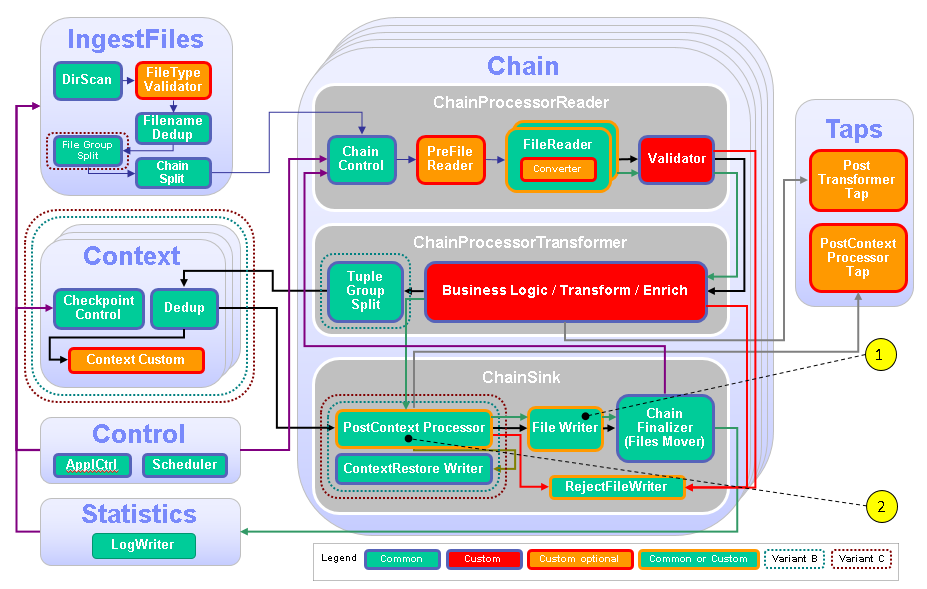
| Number | Functional Block | What needs to be customized? |
|---|---|---|
| 1 | FileWriter | Configure the FileWriter and enable the TableFileWriter for two tables. |
| 2 | ChainSink/PostContextDataProcessor | Custom code is necessary to convert from record stream type to table stream type. |
Configuration
You do all configuration settings in the same manner as you did it in the previous modules. Expand teda.demoapp/Resources/config in the Streams Studios Project Explorer and open the config.cfg file. In all later steps, this opened file is referenced when talking about config.cfg.
Tasks
The configuration and customization consists of the following tasks:
- Configure the FileWriter
- Enable the PostContextDataProcessor composite
- Customize the PostContextDataProcessor composite
Configure the FileWriter
You specify the storage type tableFile to write multiple CSV files and the table names that are used in the TableFileWriter. You configure it in the config.cfg file of the teda.demoapp project:
ite.storage.type=tableFile
ite.storage.tableNames=VOICE_CDR,SMS_CDR
Enable the PostContextDataProcessor composite
You implement custom logic that runs after the group processing but before the storage stage. You enable it in the config.cfg file of the teda.demoapp project:
ite.businessLogic.transformation.postprocessing.custom=on
Customize the PostContextDataProcessor
The custom logic has to generate table-row tuples for the two destination tables VOICE_CDR and SMS_CDR.
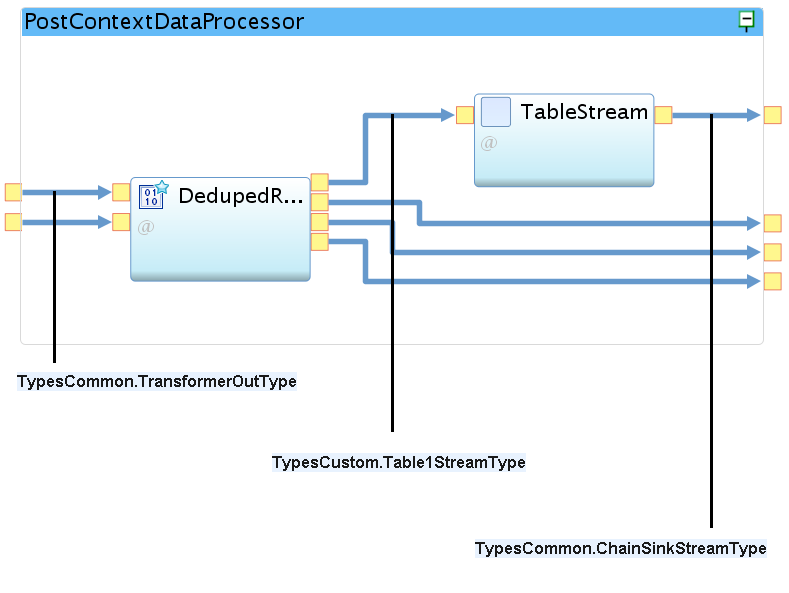
You need to transform the tuples to the composite output port stream type TypesCommon.ChainSinkStreamType, which has the following schema.
rstring tablename
rstring tablerow
TypesCommon.FileInfoBasicType
The demoapp.utility::TableRowGenerator operator converts the tuple.
It puts all attributes from first until attribute tablename of its input stream into a tablerow string attribute in its output stream.
This conversion operation requires that the input tuple schema is defined in the correct way. The input for this schema definition is the database table format.
You define the table schema in the teda.demoapp/demoapp.streams.custom/TypesCustom.spl file.
Replace the Table1 type definition:
static Table1 = tuple<
// ------------------------------------------------
// custom code begin
// ------------------------------------------------
uint8 cdrRecordType, // column recordType
uint64 cdrRecordNumber, // column recordNumber
rstring cdrCallReference, // column callReference
rstring cdrCallReferenceTime, // column callReferenceTime
uint8 cdrCallType, // column callType
rstring cdrCalledImei, // column calledIMEI
rstring cdrCalledImsi, // column calledIMSI
rstring cdrCalledNumber, // column calledNumber
uint8 cdrCalledNumberNpi, // column calledNumberNPI
uint8 cdrCalledNumberTon, // column calledNumberTON
rstring cdrCallingImei, // column callingIMEI
rstring cdrCallingImsi, // column callingIMSI
rstring cdrCallingNumber, // column callingNumber
uint8 cdrCallingNumberNpi, // column callingNumberNPI
uint8 cdrCallingNumberTon, // column callingNumberTON
rstring cdrCallingSubsFirstCi, // column callingSubsFirstCI
rstring cdrCallingSubsFirstLac, // column callingSubsFirstLAC
uint64 cdrCallingSubsFirstMcc, // column callingSubsFirstMCC
rstring cdrCauseForTermination, // column causeForTermination
rstring fileID, // column fileID
rstring cDRIDKey, // column cDRIDKey
int64 customerType, // column customerType
int64 customerID, // column customerID
rstring callStartDate, // column callStartDate
rstring callStartTime, // column callStartTime
// ------------------------------------------------
// custom code end
// ------------------------------------------------
rstring tablename // must be the last attribute (required by TableRowGenerator and used in TableFileWriter)
>;
Open the teda.demoapp/demoapp.chainsink.custom/PostContextDataProcessor.spl file.
The first customization is to add the use clause (use com.ibm.streams.teda.utility::BloomFilterTypes;) at the beginning of the file:
use demoapp.streams::*;
use demoapp.streams.custom::*;
use demoapp.functions::*;
use com.ibm.streams.teda.utility::BloomFilterTypes;
Replace the composite with the code:
public composite PostContextDataProcessor (
input
stream<TypesCommon.TransformerOutType> InRec,
stream<TypesCommon.FileStatistics> InStat;
output
stream<TypesCommon.ChainSinkStreamType> OutRec,
stream<TypesCommon.FileStatistics> OutStat,
stream<TypesCommon.RejectedDataStreamType> OutRej,
stream<TypesCommon.BundledPostContextOutputStreamType> OutTap // connected only if ite.businessLogic.group.tap=on
) {
param
expression<rstring> $groupId;
expression<rstring> $chainId;
expression<rstring> $reprocessDir;
graph
/* ***********************************************************************************
* Schema change, prepare for table row, format conversion
*
* Use the enriched record to build the table row, which is for DB load.
* Map attributes from enriched record to the table schema containing attributes
* in same sequence as the columns are in DB.
*
*************************************************************************************/
(
stream<TypesCustom.Table1StreamType> changedRec as OutStream;
stream<InStat> OutStat;
stream<TypesCommon.RejectedDataStreamType> OutRej;
stream<TypesCommon.BundledPostContextOutputStreamType> OutTap as TapStream // use only if ite.businessLogic.group.tap=on
) as DedupedRecord = Custom(InRec; InStat) {
logic
state: {
mutable int64 detectedRecordDuplicates = 0l;
}
onTuple InRec: {
// ------------------------------------------------
// custom code begin
// ------------------------------------------------
if (BloomFilterTypes.unique == bloomFilterResult) { // attribute is only available if ite.businessLogic.group.deduplication=on
mutable OutStream otuple = {};
// Fill the table schema (TypesCustom.Table1StreamType) with attributes from input stream InRec
assignFrom(otuple, InRec);
otuple.fileID = ""; // not taken from input stream, set it to empty string as column value
otuple.cDRIDKey = ""; // not taken from input stream, set it to empty string as column value
otuple.tablename =(cdrRecordType == 1ub ? "VOICE_CDR" : "SMS_CDR");
// submit to TableRowGenerator to transform the tuple to the table row attribute
submit(otuple, OutStream);
} else {
// send rejected tuple
mutable OutRej rejDuplicate = {};
rejDuplicate.filename = InRec.filename;
rejDuplicate.readerLinenumber = InRec.readerLinenumber;
rejDuplicate.rejectreason = (uint32)TypesCustom.rrRecordDuplicate;
//assignFrom(rejDuplicate.readerOutput, InRec); // if ite.storage.rejectWriter.custom=on
submit(rejDuplicate, OutRej);
}
// ------------------------------------------------
// custom code end
// ------------------------------------------------
}
onTuple InStat: {
// ------------------------------------------------
// custom code begin
// ------------------------------------------------
// update statistics with detected duplicates
InStat.recordDuplicates += detectedRecordDuplicates; // attribute is only available if ite.businessLogic.group.deduplication=on
// ------------------------------------------------
// custom code end
// ------------------------------------------------
// forward statistic tuple
submit(InStat,OutStat);
// reset member
detectedRecordDuplicates = 0l;
}
onPunct InRec: {
if (currentPunct() == Sys.WindowMarker) {
// send punctuation
submit(Sys.WindowMarker, OutStream);
submit(Sys.WindowMarker, OutRej);
submit(Sys.WindowMarker, TapStream);
}
}
}
/* ************************************************************************************
* Build the table row tuple
*
* Just table row (the whole record is one rstring) and tablename are of interest.
* We configured ITE for table file sinks with the parameter ite.storage.type=tableFile.
* TableRowGenerator takes all attributes until attribute tablename and build
* a tablerow (rstring) as expected in CSV file for DB loading
**************************************************************************************/
(stream<TypesCommon.ChainSinkStreamType> OutRec) as TableStream = demoapp.utility::TableRowGenerator(changedRec) {}
}
Building and starting the ITE application
After restructuring the project, it is best practice to clean the project before starting a new build process. To do so, select on the Streams Studio main menu Project > Clean… and select the teda.demoapp project. Press OK.
You need to do the same steps as in Module 7: Starting the applications to launch the applications and to process the input files.
Note:
If your Lookup Manager is still running and the lookup data was loaded already before, then you can launch the ITE application and trigger the restart command in the control directory. In this case the init command does not need to be processed again in order to synchronize the Lookup Manager and ITE applications.
Change into <WORKSPACE>/teda.lookupmgr/data/control directory and create the appl.ctl.cmd file with content of the
desired command, in our case: restart,demoapp.
cd <WORKSPACE>/teda.lookupmgr/data/control
echo 'restart,demoapp' > appl.ctl.cmd
ITE application and Lookup Manager application will establish a control sequence where at the end both applications are in RUN state using the data already available, without reload.
Discussing the results
Refresh and expand the data/out/load folder of the ITE application after processing the input files. You find some table files output there:
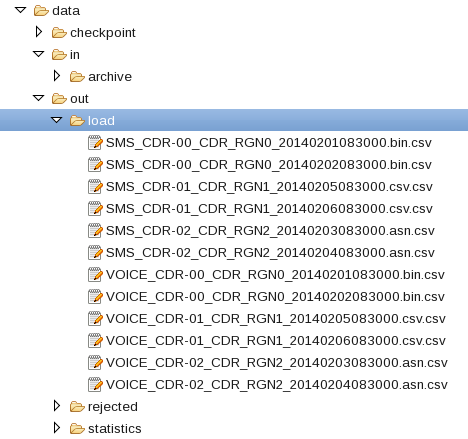
The name pattern is <tablename>-<groupID>_<input-filename>.csv
The content for SMS_CDR table files looks like:
2,56,4131002400,2014-02-01 13:05:00,3,,,186102999954,5,5,21436500000041,41400000000034,196105000045,5,6,0004,,0,00000010,,,1,34,2014-02-01,13:05:00
2,57,4131002400,2014-02-01 13:10:00,3,,,186102999954,5,5,21436500000041,41400000000034,196105000045,5,6,0004,,0,00000010,,,1,34,2014-02-01,13:10:00
2,58,4131002400,2014-02-01 13:15:00,3,,,186102999954,5,5,21436500000041,41400000000034,196105000045,5,6,0004,,0,00000010,,,1,34,2014-02-01,13:15:00
Next steps
In the next module you work with database as an optional Lookup Manager source to provide enrichment data.