Module 8 - Adding record deduplication
Edit meObjectives
In this module, you extend the ITE application that you created while following the instructions of the modules 1-7. You supply some code and configure the application that it detects duplicates of input data records.
At the end of this module, your application can detect duplicate records and prevent them from being processed again.
After completing this module you should be able to:
- Configure the file ingestion to split the files by groups
- Configure the ITE application for data deduplication
- Calculate the hash code for data deduplication
Prerequisites
You finished at least module 7 of the tutorial, in which you enriched your data by using lookups on external data.
Concepts
The input data that your application processes can contain duplicate data. Since these records contain for example charging relevant data, you don’t want the same record to be processed again. To detect duplicate records, you need to store already processed records and compare them with the record you are currently processing.
Keeping each input data record and comparing it with every new record is memory and time consuming. To reduce the amount of data to store and the time for comparison, you store only those attributes that make a record unique. With a suitable hash algorithm you build a hash value out of these attributes and store the value in a memory efficient and high-performance data structure, called bloom filter. The algorithm and the data reduction rate have an influence on the false positive rate. The more you reduce the data the higher is the false-positive rate.
Since you can’t store the hash codes for all data records you ever processed, you need to define a reasonable time to keep old hashes to find a balance between memory requirements and reliability of the data deduplication.
Another aspect is the processing speed of the whole application. If all records pass the same instance of a data deduplication unit, it can become a bottleneck and reduce the overall throughput. A solution is to define parallel deduplication groups.
Since the Mobile Switching Centers (MSCs) generate the data records, you can assume that duplicates occur only within one MSC. As a conclusion, one data deduplication unit needs to cover only the data of one MSC.
Remember, the naming schema of the data files is:
CDR_RGN<msc_id>_<YYYYMMDDhhmmss>.<type>.
The msc_id is part of the file name schema of all data files. Thus, you use that msc_id as a grouping criterion. You can also put more than one msc_id into one deduplication group. At the end, it is a question of optimizing. In this tutorial, you define one group for one msc_id.
Customization Points
The following figure and table show the points that you need to customize in the ITE application during this module or that influence the customization like the different formats and stream schemes. Other parts don’t need to be customized because it is not necessary for this module.
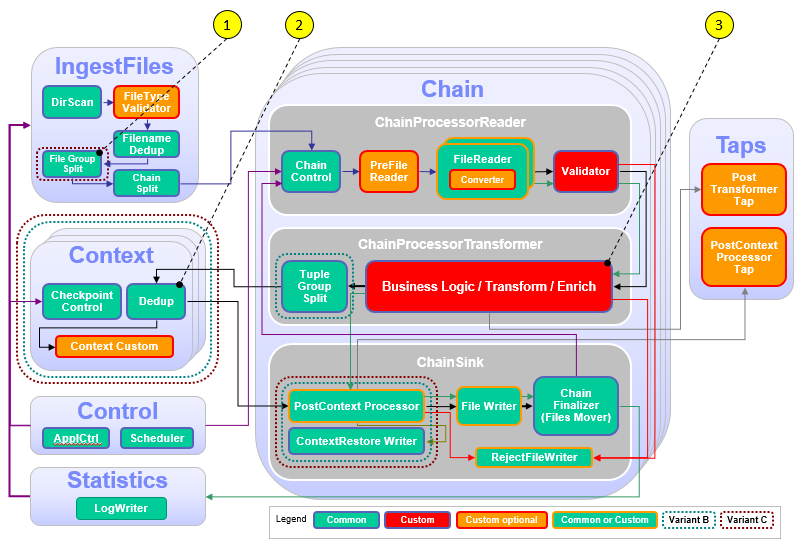
| Number | Functional Block | What needs to be customized? |
|---|---|---|
| 1 | File Group Split | Split the files into groups to have a selection criterion in subsequent processing. |
| 2 | Dedup | Tuple or record based data deduplication |
| 3 | Hash code generation | Find CDR attributes, which define a CDR uniquely and calculate a hash code out of them. |
Configuration
You do all configuration settings in the same manner as you did it in the previous modules. Expand teda.demoapp/Resources/config in the Streams Studios Project Explorer and open the config.cfg file. In all later steps, this opened file is referenced when talking about config.cfg.
Tasks
The configuration and customization consists of the following tasks:
- Customizing the file ingestion
- Configure the data deduplication
- Calculating the hash code
Customizing the file ingestion
To split the record deduplication resources or bloom filters into smaller units, you need a grouping criterion. Each SPL data tuple gets an extra attribute (groupId) that is used to route the tuple to one group.
According to the requirements, the file names have the naming schema CDR_RGN<msc_id>_<YYYYMMDDhhmmss>.<type>.
You use that msc_id to feed the grouping attribute - groupId.
To activate the framework’s feature and define the grouping pattern, you add the following line in the config.cfg file:
ite.ingest.fileGroupSplit.pattern=^.*_RGN([0-9]+)_
and modify the line:
ite.ingest.fileGroupSplit=on
The group determination pattern looks for a part of the file name that contains the msc_id, and the new groupId attribute is extracted by a regular expression (brackets). The resulting string value in brackets is used later on to identify a mapping in groups.cfg, which contains group-specific configuration values.
Example:
File name: CDR_RGN1_20140205083000.csv
Extracted msc_id: 1
Configure the data deduplication
After defining how to determine the group from the file name, you configure the groups.
Open the configuration file teda.demoapp/Resources/config/groups.cfg in the Project Explorer.
According to the requirements, you have three MSCs; each of them has its own group. Each group has a configuration line in the file. One default line must exist for all not explicitly mentioned cases. Each of these uncommented lines contains a set of parameters.
The first parameter contains the Group identifier, which comes from the groupId attribute.
The second parameter - Chains per group - defines the number of chains per group. By increasing that value, you can make use of the Streams User Defined Parallelism feature to be flexible with parallel processing per group. This value is used if no submission time parameter is available. You leave the value at 1.
The third parameter is the Maximum BloomFilter entries. When cleaning the data deduplication resource (bloom filter) every day, the sizing must be done according to the following formula:
Expected_daily_group_load * (days_to_cover + 1)
For your test, you assume a daily load of 1.000.000 CDRs for each of your groups and a deduplication history of three days. Therefore, the data deduplication resource must cover 4.000.000 entries.
Now, your groups.cfg looks like:
# Group identifier, Chains per group, Maximum BloomFilter entries
"default",1,4000000
"1",1,4000000
"2",1,4000000
After defining the conditions for the grouping, you configure the framework to instantiate parallel groups for your business logic that includes the tuple deduplication resources.
Set the following parameters in the config.cfg file:
Enable the tuple deduplication feature by enabling the tuple grouping:
ite.businessLogic.group=on
For this tutorial, you assume, that a history of three days for deduplication is sufficient:
ite.businessLogic.group.deduplication.timeToKeep=3d
Hash functions always involve the risk of false-positive matches. You can configure the bloom filter size and thus the storage need by defining the maximum false-positive rate. For this tutorial, you assume that a false-positive rate of 0.001 (1:1000) is sufficient:
ite.businessLogic.group.deduplication.probability=0.001
For a productive deployment, the false-positive rate must be 0.000001 (1:1.000.000) or lower. However, this rate requires more memory for the bloom filter.
Calculating the hash code
Each data record needs a “finger print” to be stored to detect potential duplicates. For this purpose, it is necessary to find CDR attributes, which define a CDR uniquely. You concatenate these CDR attributes to a single rstring. In a second step, you calculate a hash code out of this rstring to reduce the storage requirement.
The toolkit provides the hash function sha2hash224() that you can use for that purpose.
You do these changes in the teda.demoapp/demoapp.chainprocessor.transformer.custom/DataProcessor.spl file.
Open the file in the Streams Project Explorer and find the following custom operator with the name Check:
(
stream <I> OutRec;
stream <TypesCommon.BundledTransformerOutputStreamType> OutTap;
stream <TypesCommon.RejectedDataStreamType> EnrichFailed
) as Check = Custom (EnrichedRecords as I) {
Insert the following code on the else case of the onTuple I: clause:
else {
// calculate the hash for the deduplication from attributes which all together identify a CDR uniquely
hashcode = sha2hash224((rstring) cdrRecordNumber + cdrCallingNumber
+ cdrCalledNumber + cdrCallReferenceTime) ;
// send the record to further logic when lookup was successful
submit (I, OutRec);
}
Building and starting the ITE application
After restructuring the project, it is best practice to clean the project before starting a new build process. To do so, select on the Streams Studio main menu Project > Clean… and select the teda.demoapp project. Press OK.
You need to do the same steps as in Module 7: Starting the applications to launch the applications and to process the input files.
Note:
If your Lookup Manager is still running and the lookup data was loaded already before, then you can launch the ITE application and trigger the restart command in the control directory. In this case the init command does not need to be processed again in order to synchronize the Lookup Manager and ITE applications.
Change into <WORKSPACE>/teda.lookupmgr/data/control directory and create the appl.ctl.cmd file with content of the
desired command, in our case: restart,demoapp.
cd <WORKSPACE>/teda.lookupmgr/data/control
echo 'restart,demoapp' > appl.ctl.cmd
ITE application and Lookup Manager application will establish a control sequence where at the end both applications are in RUN state using the data already available, without reload.
Discussing the results
Refresh and expand the data/out/rejected folder of the ITE application after processing the input files. You find some files with rejection information there:
The file name indicates which file the rejected duplicated data come from. It is the same name as the input file extended by .rej.csv.
The file starts with:
2,,5
2,,10
2,,15
The first value of each CSV line is the reject reason. The value 2 stands for rrRecordDuplicate. The second value is available for comments but remains empty in this demo project. The third value in each of these CSV lines indicates the record number of the duplicate record in the input file.
Shutting down the applications and cleaning up
Typically, you use the teda-shutdown-job jobIds command to shut down an ITE or Lookup Manager application gracefully. In preparation for the next module of the tutorial, or to repeat the processing, you can also use streamtool or Streams Studio to cancel the job. For the next steps, or if you want to repeat this module, you must remove the history of the file name deduplication, which is stored in files in the checkpoint directory. It is also recommended to clean up the control and out directories.
- Cancel ITE job and Lookup Manager job
- Remove the checkpoint, control and out directories and all its content (remember that the control folder is now under Lookup Manager’s data directory).
You can remove them from Streams Studio or command line:
cd WORKSPACE/teda.demoapp/data
rm -rv checkpoint out
cd WORKSPACE/teda.lookupmgr/data
rm -rv control out
Optionally, you can close the Monitoring GUI.
Next Steps
In the next module you add a custom campaign logic implementation in the ITE application. You can skip this step and continue with adding table format output to the application.