Common Streams transforms
Edit meThis section will discuss how to use the most common functions and transforms in the Streams Python API to analyze your data.
- Introduction
- Creating a data source
- Creating data sinks
- Filtering data from the stream
- Viewing the contents of a
Stream - Windows: transforming subsets of data
- Transforming data with custom logic
- Keeping state information
- Splitting streams
- Joining streams
- Sharing data between Streams applications
- Defining a stream’s schema
Key concepts
A Streams application is a directed graph that always starts with a source Stream. This Stream is processed and analyzed using various transforms, ultimately getting sent to a data sink such as a database or file. You might remember the following animation from the previous section:
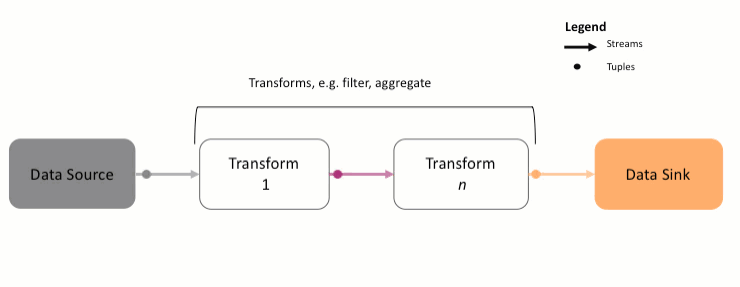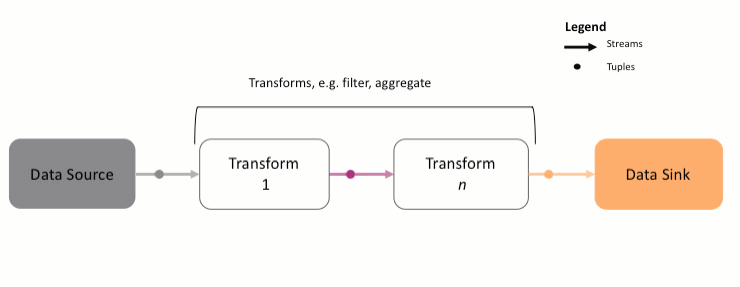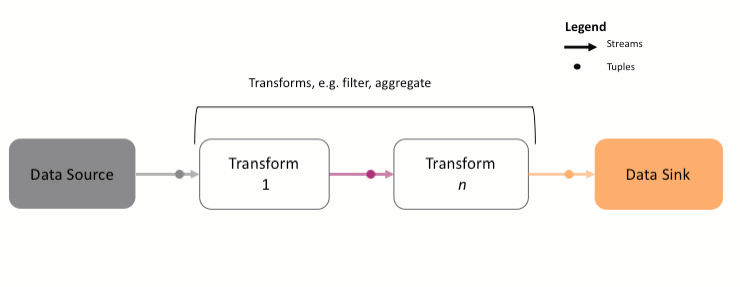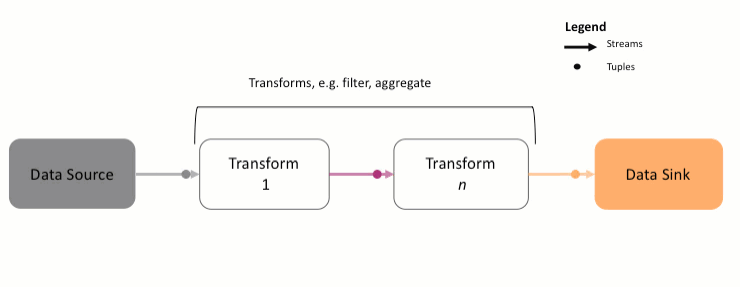
As shown above,
- The data source is a Python class or function that will produce the data to be analyzed. It could be data from Kafka, a file, database, etc. That data is converted to a
Streamobject and is called the sourceStream. - The source
Streamis processed by one or more transforms. A transform might compute the average of the data on aStream, filtering out bad data, and so on. - Each transform produces another
Streamas output, which is then forwarded to the next transform. - The last
Stream, containing the results, is sent to a data sink, another function that saves the data to an external system.
Let’s look at a very simple application that demonstrates this concept:
def get_readings():
while True:
yield {"id": "sensor_1", "value": random.gauss(0.0, 1.0)}
topo = Topology("temperature_sensor")
src = topo.source(get_readings) # create a source Stream
src.for_each(print) # print the data on the stream
Sample output:
{"id": "sensor_1", "value":-0.11907886745291935}
{"id": "sensor_1", "value":-0.24096558784475972}
...
The preceding code defines a Topology, or application, that generates some data and prints it, as described by the following graph:
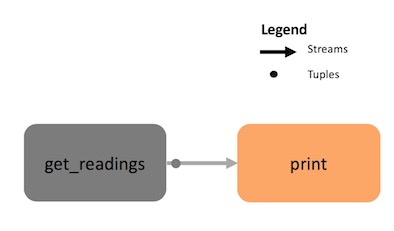
The first few lines define the get_readings function, which produces the data that will be analyzed. The data is a series of id, value pairs.
Calling Topology.source() creates the source Stream for the application, called src.
The src Stream contains the data produced by get_readings.
The for_each transform uses the print function to process the data in the src Stream. That is why the application prints the id, value pairs generated by get_readings.
Using the for_each transform to print the data in the src Stream is a basic transformation. The rest of this section will cover more complex transforms and best practices.
More information
Find detailed information about processing Streams of data in the documentation.
A note about execution
The Python API is used to create an application that can be executed on the Streams runtime. Thus, callables such as the get_readings function are not invoked until the created application is executed on the Streams runtime.
It is especially important to remember this if the Python application is created on a different host than the host where it will be executed, that is, where Streams is installed. For example, if the get_readings function opens a file, that file must actually exist on the host where Streams is running. See Working with files for an example of using local files.
Creating data sources
As mentioned, applications always begin by creating a source Stream containing the data you want to process.
To create the source Stream:
- Write a callable, such as a function or a class, that will connect to the external system and return an iterable.
- Create your source
Streamby passing the callable toTopology.source()
Example of the basic pattern:
class DbAdapter
def __call__(self):
#connect to db/site/e.t.c
# return data
topo = Topology()
incoming_data = topo.source(DbAdapter())
Note that adapters exist for common systems, which you can use instead of writing your own function.
Ingesting data from popular systems
If you want to process data from one of the following systems, you can use the corresponding Streams Python package instead of writing your own function.
| Application/System | Package |
|---|---|
| CSV File on local file system | streamsx.standard and Python standard libraries, see the Working with files section |
| Hadoop File System (HDFS) | streamsx.hdfs |
| Kafka (IBM Event Streams) | streamsx.kafka |
| MQTT | streamsx.mqtt |
| S3 Object Storage (IBM Cloud Object Storage) | streamsx.objectstorage |
| HTTP servers | streamsx.inet |
| streamsx.service, Cloud Pak for Data 3.5+ | |
| JDBC Database | streamsx.database |
Note:
With the exception of the streamsx.service module, these packages are not part of the streamsx package and must be installed using pip.
Also, the list above does not include adapters that only support writing to the external system or other general utilities. See the IBM Streams page on PyPi for the most up to date list of available packages.
Creating your own source function/callable
The callable passed to Topology.source() must:
- Take no arguments, and,
- Return an iterable, such as a list.
How it works
- When the Streams runtime begins running your application, the callable, (e.g. the
get_readingsfunction) is invoked and it returns an iterable. - The runtime then iterates through the available data by repeatedly calling next on the iterable. Each returned item that is not
Noneis submitted as a tuple for downstream processing. - When or if the iterator throws a
StopException, no more tuples appear on the source stream.
Example: Fetch data repeatedly using a blocking source
If you have to repeatedly connect to an external system for data, use yield within a loop to repeatedly fetch and return data:
class Readings(object):
def __call__(self):
while True:
next_tuple = poll_for_data()
yield next_tuple
topo = Topology("readings")
incoming_data = topo.source(Readings())
Functions vs. callable classes
You can implement your source callable as a function or a callable class. Using a callable class is the recommended option because it allows you to keep state and also restore state in the event of an outage. Let’s see an example of the difference.
The use case is tracking recent changes to Wikipedia. The data source, Wikipedia event streams, is a live stream of recent updates and changes. The source callable will use the Python Server Side Event (SSE) client to retrieve the data from Wikipedia.
The source callable could be a simple function or a callable class.
Here’s an example of a simple function:
from sseclient import SSEClient
import logging
import json
import streamsx.ec
from streamsx.topology.topology import Topology
import streamsx.topology.context
def wikipedia_stream():
eventSource = SSEClient("https://stream.wikimedia.org/v2/stream/recentchange")
while True:
raw_event= next(eventSource)
if raw_event.id == None: continue
try:
parsed_json = json.loads(raw_event.data)
event = {"ts": parsed_json["timestamp"],
"user": parsed_json["user"], "type"
"page": parsed_json["meta"]["uri"],
"title": parsed_json["title"]}
yield event
# Check if the application has shut down between emitted events
if streamsx.ec.shutdown().wait(0.05): break
except ValueError: continue
topo = Topology(name="TrackWikipediaEdits")
source = topo.source(wikipedia_stream, name="WikipediaDataSource")
source.print()
Callable class example:
from sseclient import SSEClient
import logging
import json
import streamsx.ec
class WikipediaReader(object):
def __init__(self, url='https://stream.wikimedia.org/v2/stream/recentchange', filterWiki=None):
# called when the topology is declared
self.sseURL = url
self.counter = 0
self.filterWikis = filterWiki
def __enter__(self):
# Application is starting on the Streams runtime,
self.eventSource = SSEClient(self.sseURL)
logging.getLogger("WikipediaSource").info("INFO: Wikipedia Source starting up")
def __exit__(self, exc_type, exc_value, traceback):
# called to handle an exception or shutdown
if exc_type or exc_value or traceback:
#decide if the exception can be ignored
#return True to suppress and False otherwise
logging.getLogger("WikipediaSource").warning("WARN: Some exception")
else:
#Process is shutting down
return False
def __call__(self):
while True:
# Submit a tuple in each iteration:
event = next(self.eventSource)
if event.id == None: continue
try:
data = json.loads(event.data)
event = {"ts": data["timestamp"],
"user": data["user"],
"type": data["type"],
"page": data["meta"]["uri"],
"title": data["title"]}
yield event
# Check if the application has shut down between emitted events
if streamsx.ec.shutdown().wait(0.005): break
except ValueError: continue
Advantages of using a callable class
A comparison of the preceeding two examples shows that although WikipediaReader.__call__ is similar to the wikipedia_stream function, the WikipediaReader class also has __enter__ and __exit__ functions.
-
The
__enter__function is called by the Streams runtime whenever the process executing your application is started or restarted. This allows you to perform any necessary initialization, such as creating a connection to a database. This example initialized theSSEClientobject. You could also define metrics, or, in the case of a restart due to system outage, restore any previously saved state. -
Similarly, the
__exit__function allows you to handle exceptions that occurred in the__call__function, and also perform any cleanup when the process is shutting down.
Note that __enter__ is invoked at a different time from the constructor, __init__. The class constructor is called when the Topology is declared. This is when the Streams application is being created and before it is compiled. The __enter__ function is called after the application has been successfully compiled and is being executed within the Streams runtime.
Simple iterable sources: Lists
Used when you have a finite set of data to analyze, e.g. a list. The iterable is returned directly by the function passed to Topology.source().
# Open a tar file and return list of file names
def get_log_files():
file_names = []
with tarfile.open('/path/to/logs.tar.gz') as tar_file:
tar_file.extractall()
file_names = tar_file.getnames()
return file_names
Note: In the above example, the logs.tar.gz file must be present on the host where Streams is installed. The following section presents an example of using local files in your Streams application.
Working with files
Reading from a file or using a file within your Streams application can be done using any of the built-in file handling functions in Python.
However, you must use Topology.add_file_dependency to ensure that the file or its containing directory will be available at runtime.
Note: If you are using IBM Cloud Pak for Data , this post discusses how to use a data set in your Streams Topology.
topo = Topology("ReadFromFile")
topo.add_file_dependency("/home/streamsadmin/hostdir/mydata.txt" , "etc")
This will place the file within the etc folder of the application bundle.
At runtime, the full path to mydata.txt will be:
streamsx.ec.get_application_directory() + "/etc/mydata.txt`
The following are some complete examples.
Using data from a file as your data source
This is a basic example of reading a file line by line:
import streamsx.ec
class FileReader:
def __init__(self, file_name):
self.file_name = file_name
def __call__(self):
# iterate over file contents
with open(streamsx.ec.get_application_directory()
+ "/etc/" + self.file_name) as handle:
for line in handle:
yield line.strip()
file_name = "mydata.txt"
topo = Topology("ReadFromFile")
topo.add_file_dependency("/home/streamsadmin/hostdir/" + file_name , "etc")
lines_from_file = topo.source(FileReader(file_name))
lines_from_file.print()
The FileReader class uses streamsx.ec.get_application_directory() to retrieve the path to the file on the Streams host, and then returns the file’s contents one line at a time.
CSV Files
The FileReader class can easily be extended to read CSV data. For example, if your CSV file had the following format:
timestamp,max,id,min
1551729580087,18,"8756",8
1551729396809,0,"6729",0
1551729422809,25,"6508",5
You could define a new class to read each line into a Stream of dicts as follows:
class CSVFileReader:
def __init__(self, file_name):
self.file_name = file_name
def __call__(self):
# Convert each row in the file to a dict
header = ["timestamp","max", "id", "min"]
with open(streamsx.ec.get_application_directory()
+ "/etc/" + self.file_name) as handle:
reader = csv.DictReader(handle, delimiter=',',
fieldnames=header)
#Use this to skip the header line if your file has one
next(reader)
for row in reader:
yield row
topo = Topology(name="CSVFileReader")
topo.add_file_dependency("path/on/local/fs/mydata.txt" , "etc")
lines = topo.source(CSVFileReader("mydata.txt"))
lines.filter(lambda tpl: int(tpl["min"]) >= 5).print()
Sample output:
{'min': '18', 'id': '8756', 'max': '26', 'timestamp': '1551729580087'}
{'min': '5', 'id': '6508', 'max': '25', 'timestamp': '1551729422809'}
Using streamsx.standard for reading and writing of files
Another option to work with files in your streaming application is offered by the Python module streamsx.standard.
In the following sample, the streamsx.standard.files.CSVReader is used to read a file in the source callable. For this, import the python module like below:
import streamsx.standard.files as files
The streamsx.standard.files.CSVReader accepts the file parameter either set as relative path to application directory or as absolute path. In this sample the file is added to the application bundle and the Streams application reads this file at runtime from the application directory.
For example, if your CSV file had the following format:
1551729580087,18,"8756",8
1551729396809,0,"6729",0
1551729422809,25,"6508",5
Your complete application is contained in a single file, csv_reader_sample.py.
from streamsx.topology.topology import Topology
from streamsx.topology import context
from streamsx.topology.context import submit, ContextTypes
import streamsx.standard.files as files
from typing import NamedTuple
topo = Topology(name="CSVFileReader")
input_file = 'path/on/local/fs/mydata.csv'
# add sample file to etc dir in bundle
topo.add_file_dependency(input_file, 'etc')
# schema of the CSV file
class SampleSchema(NamedTuple):
time_stamp: int
max: int
id: str
min: int
# use file name relative to application dir
lines = topo.source(files.CSVReader(schema=SampleSchema, file='etc/mydata.csv'))
lines.filter(lambda tpl: int(tpl.min) >= 5).print()
# submit the application
context.submit(ContextTypes.STANDALONE, topo)
Sample output:
SampleSchema(time_stamp=1551729580087, max=18, id='8756', min=8)
SampleSchema(time_stamp=1551729422809, max=25, id='6508', min=5)
Itertools
The Python module itertools implements a number of iterator building blocks that can therefore be used with the source transform.
Infinite counting sequence
The function count() can be used to provide an infinite stream
that is a numeric sequence. The following example uses the default start of 0 and step of 1 to produce a stream of 1,2,3,4,5,....
import itertools
def infinite_sequence():
return itertools.count()
Infinite repeating sequence
The function repeat() produces an iterator that repeats the same value, either for a limited number of times or infiintely.
import itertools
# Infinite sequence of tuples with value A
def repeat_sequence():
return itertools.repeat("A")
Reference
Filtering data
To select which tuples from on a Stream are passed on to the next transform, use the filter transform on a Stream object. The filtering is done based on a provided callable object. The Stream.filter() function takes as input a callable object that takes a single tuple as an argument and returns True or False.
Filtering is an immutable transform. When you filter a stream, the tuples are not altered. (If you want to alter the type or content of a tuple, see Transforming data.)
For example, say you have a source function that returns a set of four words from the English dictionary. However, you want to create a Stream object of words that do not contain the letter “a”.
To achieve this:
- Define a
Streamobject calledwordsthat is created by calling a function that generates a list of four words. (For simplicity, specify asourcefunction that returns only four words.) Define the following functions in thefilter_words.pyfile:def words_in_dictionary(): return {"qualify", "quell", "quixotic", "quizzically"} def does_not_contain_a(tuple): return "a" not in tuple - Next, define a topology and a stream of Python strings in
filter_words.py:topo = Topology("filter_words") words = topo.source(words_in_dictionary) - Define a
Streamobject calledwords_without_aby passing thedoes_not_contain_afunction to thefiltermethod on thewordsStream. This function is True if the tuple does not contain the letter “a” or False if it does. Include the following code in thefilter_words.pyfile:words = topo.source(words_in_dictionary) words_without_a = words.filter(does_not_contain_a)
The Stream object that is returned, words_without_a, contains only words that do not include a lowercase “a”.
The complete application
Your complete application is contained in a single file, filter_words.py.
from streamsx.topology.topology import Topology
import streamsx.topology.context
def words_in_dictionary():
return {"qualify", "quell", "quixotic", "quizzically"}
def does_not_contain_a(tuple):
return "a" not in tuple
def main():
topo = Topology("filter_words")
words = topo.source(words_in_dictionary)
words_without_a = words.filter(does_not_contain_a)
words_without_a.for_each(print)
streamsx.topology.context.submit("STANDALONE", topo)
if __name__ == '__main__':
main()
Sample output
Run the python3 filter_words.py script.
The contents of your output looks like this:
quixotic
quell
Reference
Split a stream into matching and non-matching streams
You can invoke the filter transform on a Stream object when you want to split tuples to a matching stream and non-matching stream.
In the former sample Filtering data from the stream the non-matching tuples are rejected. In this section the sample application demonstrates how to split the stream into 2 streams, one stream contains the tuples matching the filter condition and the second stream contains the other tuples.
To achieve this:
- Add the parameter
non_matching=Trueto thefiltermethod on thewordsStream and define two output streams calledwords_without_aandwords_with_a.words_without_a, words_with_a = words.filter(does_not_contain_a, non_matching=True)
The complete application
Your complete application is contained in a single file, filter_words_split.py.
from streamsx.topology.topology import Topology
import streamsx.topology.context
def words_in_dictionary():
return {"qualify", "quell", "quixotic", "quizzically"}
def does_not_contain_a(tuple):
return "a" not in tuple
def main():
topo = Topology("filter_words")
words = topo.source(words_in_dictionary)
words_without_a, words_with_a = words.filter(does_not_contain_a, non_matching=True)
words_without_a.print(tag='MATCHING')
words_with_a.print(tag='NON_MATCHING')
streamsx.topology.context.submit("STANDALONE", topo)
if __name__ == '__main__':
main()
Sample output
Run the python3 filter_words_split.py script.
The contents of your output looks like this:
NON_MATCHING: quizzically
MATCHING: quell
NON_MATCHING: qualify
MATCHING: quixotic
Reference
Creating data sinks
Often, you want to preserve the tuples on the Stream object as output. For example, you can use a Python module to write the tuple to a file, write the tuple to a log, or send the tuple to a TCP connection.
For example, you can create a sink function that writes the string representations of a tuple to a standard error message.
Sample application
To achieve this:
- Define a
Streamobject calledsourcethat is created by calling a function calledsource_tuplesthat returns a list of string values. (For simplicity, specify asourcefunction that returns “tuple1”, “tuple2”, “tuple3”). - Define a
sinkfunction that uses theprint_stderrfunction to write the tuples to stderr.
Include the following code in the sink_stderr.py file:
from streamsx.topology.topology import Topology
import streamsx.topology.context
import sys
def source_tuples():
return ["tuple1", "tuple2", "tuple3"]
def print_stderr(tuple):
print(tuple, file=sys.stderr)
sys.stderr.flush()
def main():
topo = Topology("sink_stderr")
source = topo.source(source_tuples)
source.for_each(print_stderr)
streamsx.topology.context.submit("STANDALONE", topo)
if __name__ == '__main__':
main()
Tip: If the for_each transform prints to the console, ensure the output to stdout or stderr is flushed afterward by calling sys.stdout.flush() or sys.stderr.flush().
Sample output
Run the python3 sink_stderr.py script.
The contents of your stderr console look like this:
tuple1
tuple2
tuple3
Viewing the contents of a Stream
You may have already used Stream.print() to see the data on a given Stream. A more practical way to do so is to use a View.
A View is a connection to a particular Stream in a running application that allows you to see a sample of the data in the Stream.
Views can be defined in an SPL with the @view annotation, or in Python with the Stream.view function.
Once the application is running, you can use the View to observe the data on the stream. Additionally, Views can also be added at runtime to a job, with some exceptions.
To add a view or inspect the data in a View, you can also use the Streams Console or the Job Graph in IBM Cloud Pak for Data.
Quick facts about views
- Views provide a sample of the data on a Stream, and not all the tuples on the Stream.
- Use a View to fetch data from a Stream only while the application is running.
- The data retrieved by the View is read-only, so you cannot use a View to change the tuples on a Stream.
Limitation: Once the application is running, you cannot add a view on any Streams that do not use a Structured Schema.
Creating a View
Given a Stream object, use Stream.view() to create a View object for that Stream.
input_stream = topo.source(my_src_function)
source_view = input_stream.view(name="Input", description="Sample of tuples in the input stream")
How to use a View
To view or observe the data in a View, you can use the Streams Console or the Job Graph in Cloud Pak for Data.
You can also programmatically access the data in a View once the application is running using the View object you created.
Here are the basic steps.
-
The
Viewstores the data it retrieves from theStreamon aQueue. Create this queue usingview.start_data_fetch:tuple_queue = my_results_view.start_data_fetch - Access the tuples:
- Option 1: Fetch a group of tuples using
view.fetch_tuples():tpls = view.fetch_tuples(max_tuples=10) print("Received " + str(len(tpls)) + " tuples from the Stream") - Option 2: Iterate over the items in the returned queue:
try: print("Fetching data from view") tuple_queue = view.start_data_fetch() for i in range (0, 100): tpl = tuple_queue.get() print("Tuple from the stream: " + str(tpl)) except: raise finally: view.stop_data_fetch() - Option 3: Create a live grid of data on the
Streamusingview.display(). This is only supported from a Jupyter notebook with ipywidgets installed. - Option 4: Examine the stream of data from the Streams Console or Job Graph.
- Option 1: Fetch a group of tuples using
- Call
view.stop_data_fetchto stop fetching data from theStream. Views use HTTP connection to the running job, so this closes the connection.
Sample application
This application demonstrates creating a View and printing the data it returns.
The input is a stream of numbers. The application’s goal is to increment each tuple by 10.
We create two Views, one for the input and one for the result Stream.
topo = Topology("ViewDemo")
src_stream = topo.source(Numbers())
# create a view of the source data
src_view = src_stream.view(name="Numbers stream", description="Unfiltered input stream")
# Update each value in the stream by 10
increment_stream = src_stream.map(increment, name="Increment")
# Create a view to access the result stream
results_view = increment_stream.view(name="Increment_Stream",
description="Incremented tuples",
start=True)
increment_stream.publish(topic="Increment")
submit_topology(topo)
from streamsx.topology.topology import Topology
from streamsx.topology import context
import time
import random
import itertools
class Numbers(object):
def __call__(self):
for num in itertools.count(1):
time.sleep(0.5)
yield {"value": num, "id": "id_0"}
def submit_topology(topo):
cfg = {}
cfg[context.ConfigParams.SSL_VERIFY] = False
# submit the application
result = context.submit("DISTRIBUTED", topo, config=cfg)
print("Submitted topology successfully " + str(result))
def increment(tpl):
tpl["increment"] = tpl["value"] + 10
return tpl
topo = Topology("ViewDemo")
src_stream = topo.source(Numbers())
# create a view of the source data
src_view = src_stream.view(name="Numbers stream", description="Unfiltered input stream")
# Update each value in the stream by 10
increment_stream = src_stream.map(increment, name="Increment")
# Create a view to access the result stream
results_view = increment_stream.view(name="Increment_Stream",
description="Incremented tuples",
start=True)
increment_stream.publish(topic="Increment")
submit_topology(topo)
# Fetch tuples from the queue
try:
print("Fetching data from view")
tuple_queue = results_view.start_data_fetch()
# Use this line to iterate indefinitely
# for tpl in iter(queue.get, None):
for i in range (0, 10):
tpl = tuple_queue.get()
print("Tuple from the stream: " + str(tpl))
except:
raise
finally:
results_view.stop_data_fetch()
Fetch data from the View
Once the applicaton is running, use the View to fetch data from the Stream:
try:
print("Fetching data from view")
tuple_queue = results_view.start_data_fetch()
# Use this line to iterate indefinitely
# for tpl in iter(queue.get, None):
for i in range (0, 10):
tpl = tuple_queue.get()
print("Tuple from the stream: " + str(tpl))
except:
raise
finally:
results_view.stop_data_fetch()
Output:
Tuple from the stream: {'value': 51, 'id': 'id_0', 'increment': 61}
Tuple from the stream: {'value': 52, 'id': 'id_0', 'increment': 62}
Tuple from the stream: {'value': 53, 'id': 'id_0', 'increment': 63}
Tuple from the stream: {'value': 54, 'id': 'id_0', 'increment': 64}
Tuple from the stream: {'value': 55, 'id': 'id_0', 'increment': 65}
Tuple from the stream: {'value': 56, 'id': 'id_0', 'increment': 66}
Tuple from the stream: {'value': 57, 'id': 'id_0', 'increment': 67}
Visualizing data
You can use some of the built-in tools to create a simple grid, or chart of live data. Or, create your own visualizations with the data returned by the View.
Live charts are available in the Streams Console, the Job Graph in IBM Cloud Pak for Data, and also from a Jupyter Notebook.
Display a grid of live data
Here are steps to display the data fetched by a View for the available tools.
Streams Console
- From the top left menu, expand the Streams instance, then expand the Views item in the tree.
- Find the `View` using the name you gave it at creation time.
- Hover over the `View` and click Add view grid.
IBM Cloud Pak for Data
- From the main menu, go to My Instances > Jobs.
- Find your job based on the Job id or name.
- Select View graph from the context menu action for the running job.
- A grid listing any `Views` defined in the
Topologywill be displayed below the Streams graph.
Jupyter Notebooks
UseView.display().
Requires ipywidgets and Pandas.
You should see the following output:
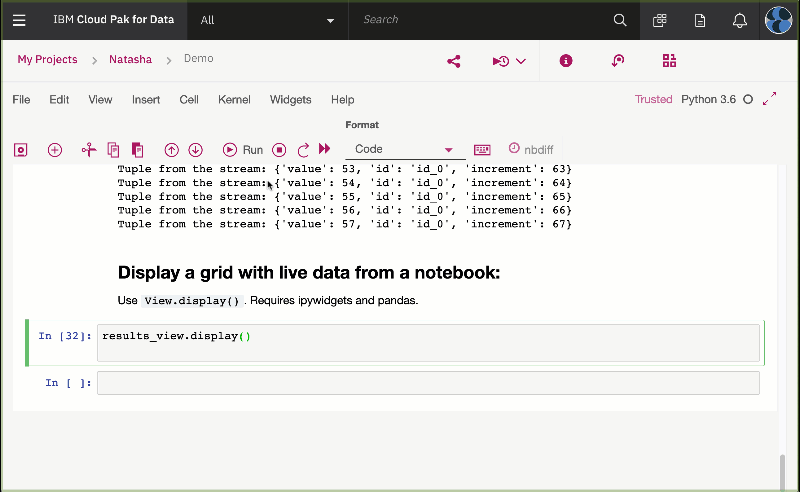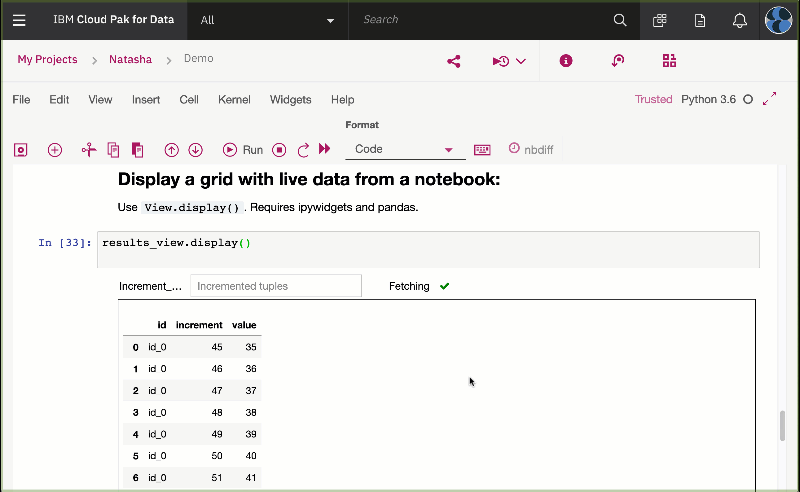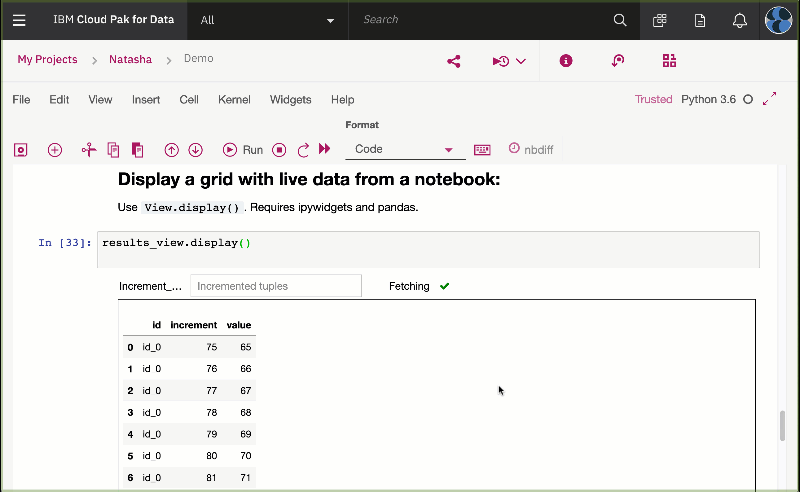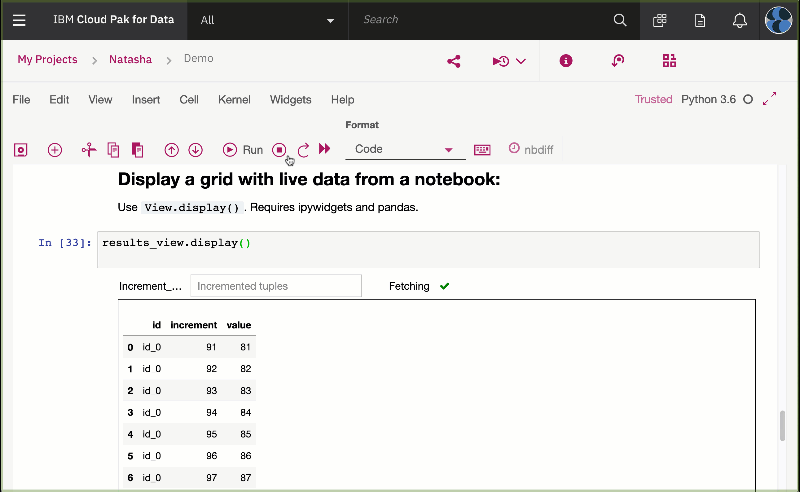 </img>
</img>
Create your own visualizations with streaming data
There are several tools for visualizing data, such as Bokeh, and Matplotlib. Regardless of the tool you choose, the principles involved in visualizing Streaming data are the same:
- Create a
Viewfor theStreamcontaining the data you want to visualize. See the preceeding instructions. - Submit the application for execution.
- Using the visualization library of your choice, create a graph or visualization object. This could be a
Figurein Matplotlib. - Use the
Viewto start fetching data from theStream. - Update the graph with the tuples returned from the
View.
Since we already have an application, the following code demonstrates steps 3-5.
It uses Matplotlib to plot the data from the results_view View created in the preceeding application.
1. Define the function to create a graph
This code creates the graph that will be display the streaming data.
See the matplotlib subplots function.
import numpy as np, math
import matplotlib.pyplot as plt
# Create a graph with the given x and y values
# and the specified title, labels etc.
# xlim and ylim are the upper boundaries of the graph
def create_plot(xvalues, yvalues, title=None, xlabel=None, ylabel=None, xlim=None, ylim=None):
fig, ax = plt.subplots()
plt.title(title)
plt.ylabel(ylabel)
plt.xlabel(xlabel)
ax.set_xlim(*xlim)
ax.set_ylim(*ylim)
ax.plot(xvalues,
yvalues, "-b", linewidth = 2, label = 'target')
return fig,ax
2. Fetch data from the view and update the graph
%matplotlib notebook
xdata = []
ydata = []
try:
tuple_queue = results_view.start_data_fetch()
# find boundaries of the graph
start = tuple_queue.get()["value"]
end = start + 100
fig, ax = create_plot([], [], title="Value vs Increment", xlabel = "Value",
ylabel = "Incremented value",
xlim = (start, end),
ylim = (start, end + 50))
for i in range(50):
tpl = tuple_queue.get()
xdata.append(tpl["value"])
ydata.append(tpl["increment"])
ax.lines[0].set_xdata(xdata)
ax.lines[0].set_ydata(ydata)
fig.canvas.draw()
except:
raise
finally:
results_view.stop_data_fetch()
Sample visualization created with Matplotlib
This image shows the above code running in a notebook.
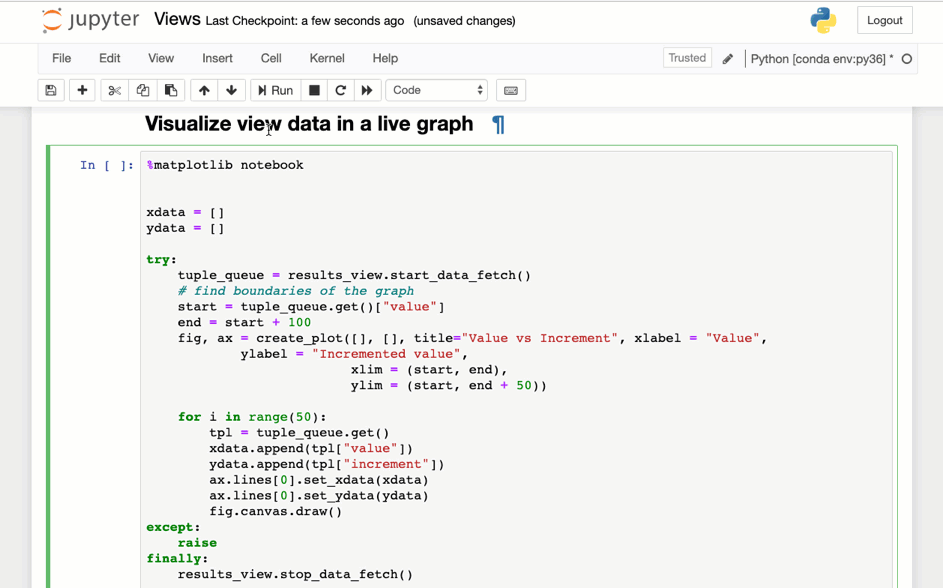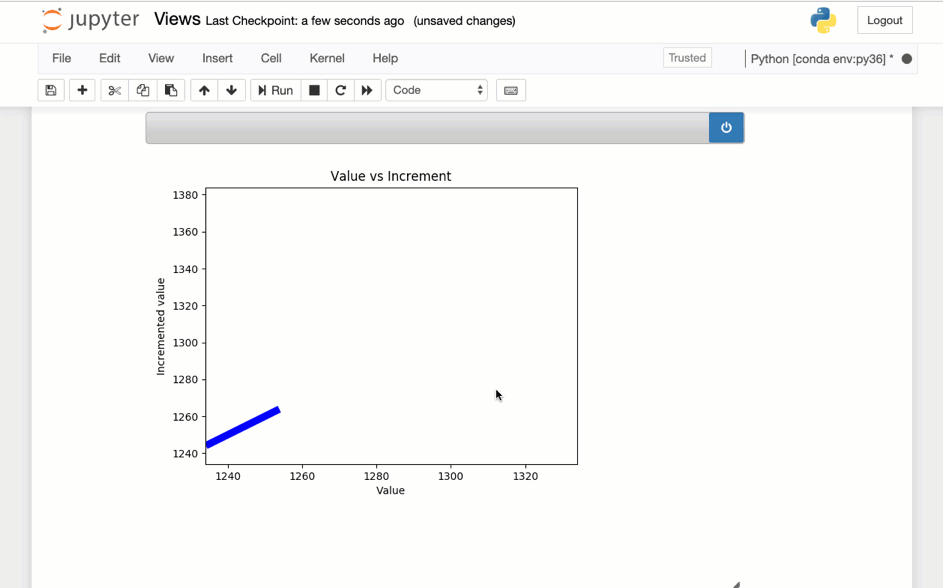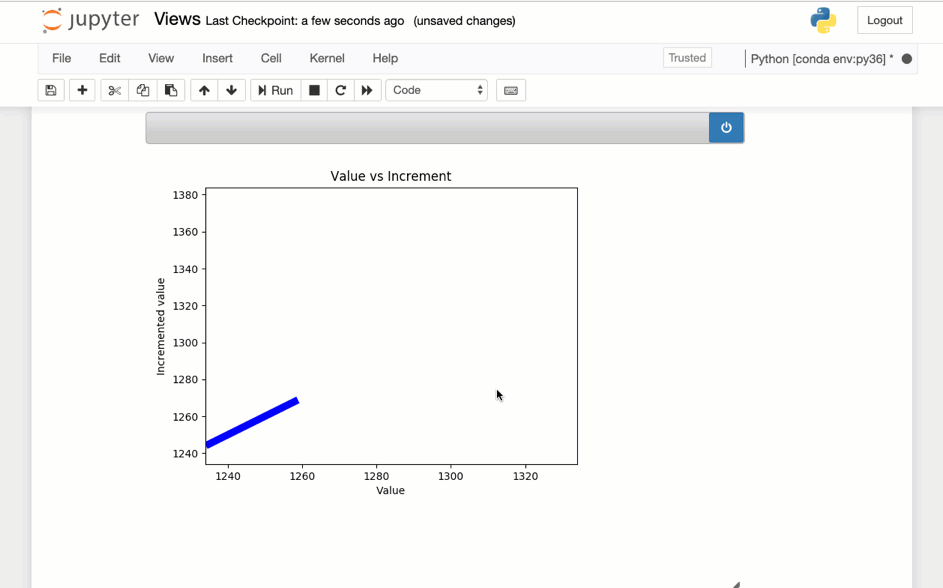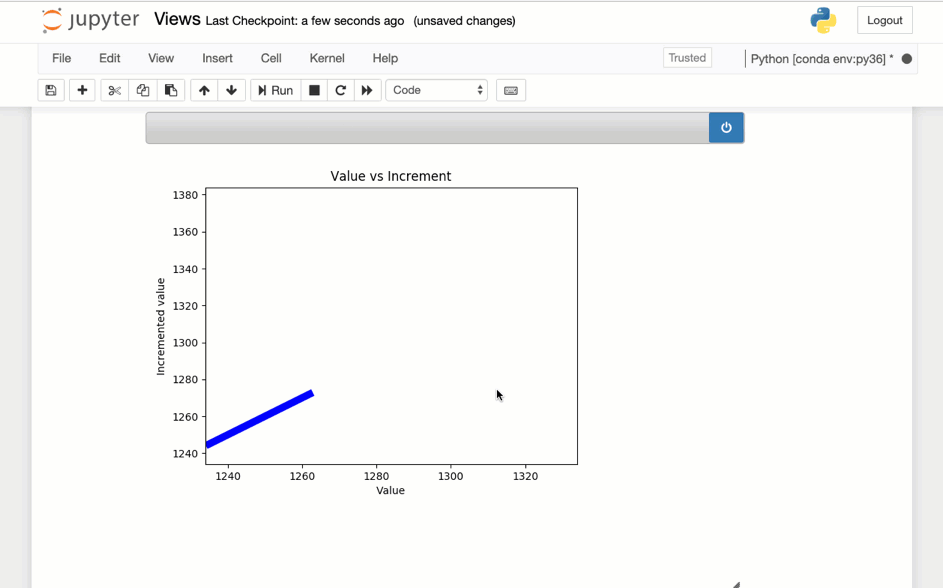
Accessing the tuples in a Stream via REST
You can fetch data from a View in a running application even if you do not have the View object. Create a View object using the REST API. The REST API allows you to connect to a View in any running application.
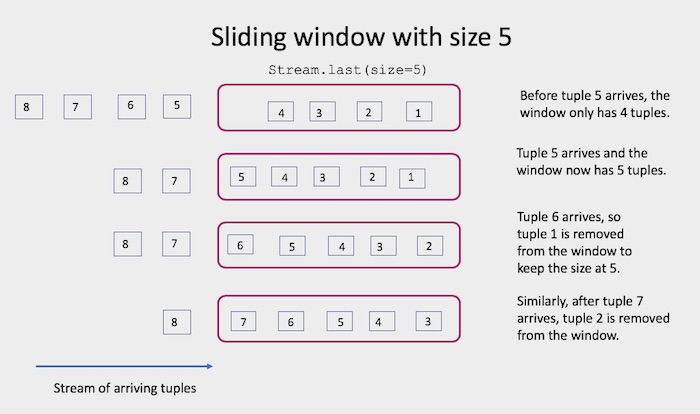
Windows: Transforming subsets of data
When working with streams of data, a common pattern is to analyze subsets of the data instead of individual tuples. For example, if you have a stream of sensor readings, you might want to find out the maximum reading for each hour, or keep the rolling average value for the last 100 readings.
These subsets of the tuples in the stream of data (last 100 readings, data for 1 hour) are called windows.
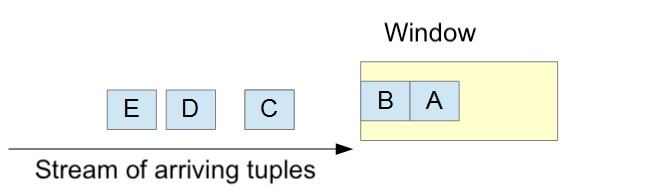
As shown above, windows are made up of a finite number of tuples. They are represented by the Window class in this API. You create a new Window by calling Stream.last() or Stream.batch().
The difference between Stream.last() and Stream.batch() will be covered later in this guide. For now, the examples will use Stream.last().
How many tuples will the window contain?
You specify how many tuples are collected into the window based on your application’s needs. You have 2 options. You can create the windows based on the number of tuples that have arrived (count-based) or on how much time elapses between tuple arrivals (time-based).
Here are examples of each option:
-
Collect the last 100 tuples, regardless of how often the data arrives. This is a count-based window.
Stream.last(size=100) -
Collect all the tuples that arrive in a 5 minute interval. This is a time-based window.
Stream.last(size=datetime.timedelta(minutes=5))Elapsed time is computed using system time. The number of tuples collected will depend on how many tuples arrive in the specified interval.
Template for using windows
Using Windows involves 3 steps:
- Given a
Streamof tuples, create aWindowusing usingStream.last()orStream.batch(). - Write a callable to process the tuples in a window and return one or more tuples containing the results. For example, if you want to compute the average of the tuples in a window, you would write a callable that takes as a parameter a list of tuples and returns a value representing the computed average. This function is called either when:
- The window is full, that is, when its size or time requirement is met,
- Or, when its trigger policy is met. We will discuss the trigger policy shortly.
The tuples in the window will be passed to this callable when it is invoked.
- Call
Window.aggregate(), passing the function from step 1. This will generate a newStreamcontaining the result tuples.
The basic code pattern is this:
def compute_average(tuples_in_window): # This is the callable
... #process data in window
topo = Topology("Rolling Average")
incoming_data = topo.source(my_src_func)
# src.last() creates a window with the last 10 tuples
rolling_average = incoming_data.last(size=10).aggregate(compute_average)
rolling_average.print()
Let’s look at a detailed example.
Simple example: compute a rolling average
This example involves taking a stream of consecutive integers and computing the average, maximum and minimum of the last 10 numbers. Here is the data source:
from streamsx.topology.topology import Topology
import streamsx.topology.context
import streamsx.ec
import time
import random
class Numbers:
def __call__(self):
for num in itertools.count(1):
yield {"value": num, "id": "id_" + str(random.randint(0,10))}
The Numbers class produces a stream of consecutively increasing integers.
Step 1: Define the Window using Stream.last()
This topology uses the Numbers class as a data source and defines a window of the last 10 tuples:
topo = Topology("Rolling Average")
src = topo.source(Numbers())
window = src.last(size=10)
Step 2: Define the processing callable
We’ll use a callable class called Average to handle the processing. When it is time to process the tuples in a window, a list of the tuples in the window are passed to this class. The Average class takes a list of tuples in the window and return a new tuple with 4 attributes: max, min,average, and count. These attributes represent the max, min, average and number of the tuples in that window, respectively.
class Average:
def __call__(self, tuples_in_window):
values = [tpl["value"] for tpl in tuples_in_window]
mn = min(values)
mx = max(values)
num_of_tuples = len(tuples_in_window)
average = sum(values)/len(tuples_in_window)
return {"count": num_of_tuples,
"avg": average,
"min": mn,
"max": mx}
Step 3: Compute the result using Window.aggregate()
Pass an instance of the Average class to the aggregate function. The aggregate function returns a new Stream with the computed rolling average.
rolling_average = window.aggregate(Average())
# Create a view to access the result stream
results_view = rolling_average.view()
After submitting this application, use this code to connect to it and display the contents:
import pandas as pd
queue = results_view.start_data_fetch()
results = []
# get a few result tuples
for i in range(15):
results.append(queue.get())
results_view.stop_data_fetch()
#display as Pandas data frame
df = pd.DataFrame(results)
print(df)
from streamsx.topology.topology import Topology
from streamsx.topology import context
import time
import random
import itertools
class Average:
def __call__(self, tuples_in_window):
values = [tpl["value"] for tpl in tuples_in_window]
mn = min(values)
mx = max(values)
num_of_tuples = len(tuples_in_window)
average = sum(values) / len(tuples_in_window)
return {"count": num_of_tuples,
"avg": average,
"min": mn,
"max": mx}
class Numbers(object):
def __call__(self):
for num in itertools.count(1):
# time.sleep(1.0)
yield {"value": num, "id": "id_" + str(random.randint(0, 10))}
topo = Topology("Rolling Average")
src = topo.source(Numbers())
window = src.last(size=10)
rolling_average = window.aggregate(Average())
# Create a view to access the result stream
results_view = rolling_average.view()
cfg = {}
cfg[context.ConfigParams.SSL_VERIFY] = False
# submit the application
context.submit("DISTRIBUTED", topo, config=cfg)
import pandas as pd
queue = results_view.start_data_fetch()
results = []
# get a few result tuples
for i in range(15):
results.append(queue.get())
results_view.stop_data_fetch()
# display as Pandas data frame
df = pd.DataFrame(results)
print(df)
This produces the following output.
Each row represents the results of one invocation of the Average class with the contents of a window.
| count | min | max | average |
|---|---|---|---|
| 1 | 1 | 1 | 1.0 |
| 2 | 1 | 2 | 1.5 |
| 3 | 1 | 3 | 2.0 |
| 4 | 1 | 4 | 2.5 |
| 5 | 1 | 5 | 3.0 |
| 6 | 1 | 6 | 3.5 |
| 7 | 1 | 7 | 4.0 |
| 8 | 1 | 8 | 4.5 |
| 9 | 1 | 9 | 5.0 |
| 10 | 1 | 10 | 5.5 |
| 10 | 2 | 11 | 6.5 |
| 10 | 3 | 12 | 7.5 |
| 10 | 4 | 13 | 8.5 |
The window size was set to 10, so we would expect that the Average callable is only called when there are 10 tuples in the window. However, looking closely at the first few result tuples, the number of tuples in the window (the count column) starts at 1 and increases by 1 until it reaches and stays at 10. This might seem strange at first, but it is actually expected behavior. Why? Because we indicated the size of the window, but not when we wanted the average to be computed, so the average is computed for every new tuple.
Trigger policy: when to update the rolling average
The previous example computed the rolling average for the last 10 tuples, but as shown above, there are initially less than 10 tuples in the window. This is because the average is being calculated whenever a new tuple arrives, even when there are less than 10 tuples in the window.
We can adjust this by setting the trigger policy. The trigger policy controls how often the processing callable is invoked, i.e. when a new calculation is triggered. This is set using Window.trigger():
window = src.last().trigger().
If the trigger policy is not specified, a window defined using Stream.last() has a default trigger of 1.
So in our example, this code:
window = src.last(size=10)
is equivalent to
window = src.last(size=10).trigger(1)
which creates a window of the last 10 tuples, calling the processing function for every new tuple. This explains why the number of tuples in the window starts at 1 and progressively increases by 1:
| count | min | max | average | |
|---|---|---|---|---|
| 1 | 1 | 1 | 1.0 | |
| 2 | 1 | 2 | 1 | 1.5 |
| 3 | 1 | 2 | 2.0 | |
| 4 | 1 | 4 | 2.5 | |
| 5 | 1 | 5 | 3.0 |
Using a trigger policy helps if there is a lot of noise in the data.
Other example use cases for the trigger policy are:
- You’d like to calculate the rolling average of values from the last hour, but only calculate it every 5 minutes. You would use a window size of 1 hour but a trigger policy of 5 minutes.
- You want to compute the maximum reported reading of the last 200 tuples, but update this value every 30 seconds. You’d use a window size of 200 with a trigger policy of 30 seconds.
Example 2: rolling average, updated at intervals
We still want to compute the rolling average of the last 10 tuples, but this time we want to update this value every 5 tuples.
Let’s change our window definition to set a trigger policy of 5 using Window.trigger:
src = topo.source(Numbers())
window = src.last(size=10).trigger(5) #Use trigger(datetime.timedelta(seconds=10)) to use a time based trigger
from streamsx.topology.topology import Topology
import streamsx.topology.context
import time
import random
import itertools
class Average:
def __call__(self, tuples_in_window):
values = [tpl["value"] for tpl in tuples_in_window]
mn = min(values)
mx = max(values)
num_of_tuples = len(tuples_in_window)
average = sum(values)/len(tuples_in_window)
return {"count": num_of_tuples,
"avg": average,
"min": mn,
"max": mx}
class Numbers(object):
def __call__(self):
for num in itertools.count(1):
#time.sleep(1.0)
yield {"value": num, "id": "id_" + str(random.randint(0,10))}
topo = Topology("Rolling Average")
src = topo.source(Numbers())
# src.last() creates a window with the last 10 tuples
rolling_average = src.last(size=10).trigger(5).aggregate(Average())
rolling_average.print()
results_view = rolling_average.view()
submission_result = streamsx.topology.context.submit("DISTRIBUTED",
topo)
All the remaining code stays the same. Re-running this application we get this output, with one row for each invocation of the Average class:
| count | min | max | average |
|---|---|---|---|
| 5 | 1 | 5 | 3.0 |
| 10 | 1 | 10 | 5.5 |
| 10 | 6 | 15 | 10.5 |
| 10 | 11 | 20 | 15.5 |
Since the values in the window are consecutive integers, it is easy to determine which tuples were in each window. For example, the first window has a min of 1, a max of 5 and a count of 5, so it is obvious it contains the integers from 1 to 5. The next window has the 10 numbers from 1 to 10, the next, from 6 to 15, and so on.
This leads to another observation, that the values in each window are not unique.
This is because the window we created is a sliding window. Stream.last() always creates a sliding window. The other kind of window is a tumbling window, which is created using Stream.batch(). What is the difference?
Unique vs. overlapping windows
If you create a window using Stream.last(), this window is a sliding window. Tuples in sliding windows can appear in more than one window. This is useful in our example above, where we are calculating the average of the last 10 tuples, every 5 tuples.
If, instead, you wish to perform the aggregation in batches, e.g. in groups of 10 unique tuples, or once per hour, then you would use a tumbling window. Tumbling windows are created using Stream.batch() and do not have a trigger policy.
With tumbling windows, the contents of the window are unique between windows. When the size requirement is reached, all the tuples in a tumbling window are processed and removed from the window. By comparison, tuples in a sliding window are processed when the trigger policy is met.
The following graphics illustrate the difference between sliding and tumbling windows using the same set of tuples.
Sliding/Overlapping windows
Use a sliding window when you want to have the aggregation re-use tuples.
Tumbling/unique windows
Use a tumbling window to process tuples in batches. Each tuple can only be used once in an aggregation.

Batch processing using tumbling windows: Example
Let’s change our previous example to use a tumbling window by using Stream.batch() instead of Stream.last().
We do not have to change the callable function or the source function, but just the window declaration.
We now have this code:
topo = Topology("Batch Average")
src = topo.source(Numbers())
batch_average = src.batch(size=10).aggregate(Average())
batch_average.print()
results_view = batch_average.view()
And this output:
| min | max | avg | count |
|---|---|---|---|
| 1 | 10 | 5.5 | 10 |
| 11 | 20 | 15.5 | 10 |
| 21 | 30 | 25.5 | 10 |
| 31 | 40 | 35.5 | 10 |
Dividing tuples in a window into a group
So far we have calcuated the average for all the tuples in a window. Sometimes, you want to divide the tuples in a window into groups and aggregate the data in the group. For example, you might want to calculate the maximum temperature reported by each sensor. There are two ways to do this:
- Simple grouping: Group the tuples manually within your processing callable and then process each group iteratively. You can use a Python library like Pandas.
- Partitioning, or grouping using subwindows: create subwindows for each group, which will be processed independently, whenever a subwindow is full.
Simple grouping
Continuing the previous example, let’s change the Averages class to compute the average for each sensor based on the last 20 readings:
import pandas as pd
import numpy as np
class Averages:
def __call__(self, items_in_window):
df = pd.DataFrame(items_in_window)
#group the data by id
readings_by_id = df.groupby("id")
#for each id, create a new DataFrame
# just computing min, max and avg for the value column
# using aggregation specifying a list of tuples specifying the aggregations
# of the format (''column_to_aggregate', aggfunc')
summary_by_id = readings_by_id["value"].agg([('max_val','max'),
('avg','mean'),
('min_val','min')])
#return a list of tuples, one for each id
result = []
for id, row in summary_by_id.iterrows():
result.append({"average": float(row["avg"]),
"min": float(row["min_val"]),
"max": float(row["max_val"]),
"id": id)})
return result
from streamsx.topology.topology import Topology
from streamsx.topology import context
import time
import random
import itertools
import pandas as pd
import numpy as np
class Averages:
def __call__(self, items_in_window):
df = pd.DataFrame(items_in_window)
#group the data by id
readings_by_id = df.groupby("id")
#for each id, create a new DataFrame
# using aggregation specifying a list of tuples specifying the aggregations
# of the format (''column_to_aggregate', aggfunc')
summary_by_id = readings_by_id["value"].agg([('max_val','max'),
('avg','mean'),
('min_val','min')])
#return a list of tuples, one for each id
result = []
for id, row in summary_by_id.iterrows():
result.append({"average": float(row["avg"]),
"min": float(row["min_val"]),
"max": float(row["max_val"]),
"id": id})
return result
class Numbers(object):
def __call__(self):
for num in itertools.count(1):
# time.sleep(1.0)
yield {"value": num, "id": "id_" + str(random.randint(0, 10))}
topo = Topology("Rolling Average With Grouping")
src = topo.source(Numbers())
window = src.last(size=20) #rolling average of last 20 readings,
rolling_average = window.aggregate(Averages()).flat_map()
# Create a view to access the result stream
results_view = rolling_average.view()
cfg = {}
cfg[context.ConfigParams.SSL_VERIFY] = False
# submit the application
result = context.submit("DISTRIBUTED", topo, config=cfg)
print("Submitted topology successfully " + str(result))
import pandas as pd
queue = results_view.start_data_fetch()
results = []
# get a few result tuples
for i in range(15):
results.append(queue.get())
results_view.stop_data_fetch()
# display as Pandas data frame
df = pd.DataFrame(results)
print(df)
The preceeding code does the following:
- Using a Pandas
DataFrame, we group the data byid - Compute the average, minimum and maximum values reported for each
idusing theaggfunction - Then return a list of tuples, one for each unique
idin the window. - The
Averagesclass is now returning aStreamwhere each tuple is a list of values. - Since we want to work with individual tuples, we use the
flat_mapfunction to convert thatStreamto aStreamof individual tuples.
rolling_average = window.aggregate(Averages()).flat_map()
# Create a view to access the result stream
results_view = rolling_average.view()
Click Full Source above for the updated source code. After running the application, we’ll get something like this:
| average | min | max | id |
|---|---|---|---|
| 72 | 71 | 73 | id_3 |
| 74 | 72 | 77 | id_8 |
| 72 | 69 | 75 | id_9 |
| 76 | 76 | 76 | id_1 |
Partitioning: dividing tuples into separate windows
So far, we have only used one window, and when the Averages class was called, all the tuples in the window were passed to it for processing. This works, but sometimes is not sufficient.
Imagine that you have 2 sensors reporting data. Sensor A, with id id_A is reporting a reading every minute, while sensor B, with id id_B only reports once every second. Maybe sensor A is stuck on a slow network.
If you created a window using Stream.last(10), more often than not, every tuple in the window will be from sensor B, since it is reporting more frequently. It would be difficult to report the average of the last 10 readings for each sensor.
Let’s see a concrete example of this problem first:
-
Change the
Numbersclass to simulate a sensor B that reports much more frequently than sensor A. Modify it so that every 9th tuple has id ‘A’ and all other tuples have id ‘B’.def get_id(count): if (count % 9 == 0): return "A" else: return "B" class Numbers(object): def __call__(self): for num in itertools.count(1): # time.sleep(1.0) yield {"value": num, "id": "id_" + get_id(num)} -
Modify the
Averagesclass to show the contents of each window by adding awindow_contentsattribute to show the ids of every tuple in the window:class Averages: def __call__(self, items_in_window): ## create a list of all the ids in the window ids_in_window = [item["id"] for item in items_in_window] df = pd.DataFrame(items_in_window) #group the data by id readings_by_id = df.groupby("id") summary_by_id = readings_by_id["value"].agg([('avg','mean')]) #return a list of tuples, one for each id result = [] for id, row in summary_by_id.iterrows(): result.append({"average": float(row["avg"]), "id": id, "window_contents": ids_in_window}) return result -
Run the application and look at its output.
average id window_contents 2115 id_A [id_B, id_B, id_B, id_B, id_B, id_A, id_B, id_B, id_B, id_B] 2114 id_B [id_B, id_B, id_B, id_B, id_B, id_A, id_B, id_B, id_B, id_B]
Looking at the window_contents attribute, the majority of the tuples in each window are from sensor B.
How can we get the average of the last 10 tuples received from sensor A?
The solution is to use a separate window for each sensor. Doing so, you will only calculate the average for a sensor when 10 tuples have been received from that sensor.
To create subwindows for each group, use Window.partition. Partitions and subwindows are used interchangeably.
For example, a partitioned tumbling window of size 10:
def getKeyForPartition(tpl):
return tpl["id"]
# define topology, etc.
window = src.batch(size=10).partition(key=getKeyForPartition)
rolling_average = window.aggregate(Averages())
All the subwindows share the defined size and trigger policy.
How it works:
- Tuples are assigned to a subwindow based on a user-defined
key, which can be a Python callable. It can be a string if a structured schema is being used. - When a tuple is received, the
keyis used to determine which subwindow the tuple belongs to. In this example, thegetKeyForPartitionfunction is called and the tuple’sidis used as the key, so every tuple with thatidwill be put in the same window. - Each subwindow will be processed when it is full, regardless of the state of the other subwindows.
- The processing callable will receive only the tuples for a specific subwindow.
Modify the example and re-run it:
# Since the Averages callable will receive the tuples already in a group,
# we no longer need the grouping using Pandas
class Averages:
def __call__(self, tuples_in_window):
ids_in_window = [item["id"] for item in tuples_in_window]
values = [tpl["value"] for tpl in tuples_in_window]
mn = min(values)
mx = max(values)
num_of_tuples = len(tuples_in_window)
average = sum(values) / len(tuples_in_window)
return {"count": num_of_tuples,
"avg": average,
"min": mn, "window_contents": ids_in_window,
"id":tuples_in_window[0]["id"],
"max": mx}
# Define a function to be used as the partitioning function
def getKey(tpl):
return tpl["id"]
...
#Modify window definition
window = src.last(size=10).partition(key=getKey)
rolling_average = window.aggregate(Averages())
from streamsx.topology.topology import Topology
from streamsx.topology import context
import time
import random
import itertools
import pandas as pd
import numpy as np
def getKey(tpl):
return tpl["id"]
class Averages:
def __call__(self, tuples_in_window):
ids_in_window = [item["id"] for item in tuples_in_window]
values = [tpl["value"] for tpl in tuples_in_window]
mn = min(values)
mx = max(values)
num_of_tuples = len(tuples_in_window)
average = sum(values) / len(tuples_in_window)
return {"count": num_of_tuples,
"avg": average,
"min": mn, "window_contents": ids_in_window,
"id":tuples_in_window[0]["id"],
"max": mx}
def get_id(count):
if (count % 9 == 0):
return "A"
else:
return "B"
class Numbers(object):
def __call__(self):
for num in itertools.count(1):
# time.sleep(1.0)
yield {"value": num, "id": "id_" + get_id(num)}
topo = Topology("Partitioned Rolling Average")
src = topo.source(Numbers())
window = src.last(size=10).partition(key=getKey)
rolling_average = window.aggregate(Averages())
# Create a view to access the result stream
results_view = rolling_average.view()
cfg = {}
cfg[context.ConfigParams.SSL_VERIFY] = False
# submit the application
result = context.submit("DISTRIBUTED", topo, config=cfg)
print("Submitted topology successfully " + str(result))
import pandas as pd
queue = results_view.start_data_fetch()
results = []
# get a few result tuples
for i in range(15):
results.append(queue.get())
results_view.stop_data_fetch()
# display as Pandas data frame
df = pd.DataFrame(results)
print(df)
Results:
| count | avg | min | max | id | window_contents |
|---|---|---|---|---|---|
| 10 | 30.2 | 25 | 35 | id_B | [id_B, id_B, id_B, id_B, id_B, id_B, id_B, id_B, id_B, id_B] |
| 10 | 31.3 | 26 | 36 | id_B | [id_B, id_B, id_B, id_B, id_B, id_B, id_B, id_B, id_B, id_B] |
| 10 | 96.5 | 56 | 137 | id_A | [id_A, id_A, id_A, id_A, id_A, id_A, id_A, id_A, id_A, id_A] |
| 10 | 32.5 | 27 | 38 | id_B | [id_B, id_B, id_B, id_B, id_B, id_B, id_B, id_B, id_B, id_B] |
Now, we see from the window_contents column that all the tuples are divided among windows by id, even though one sensor reports more frequently than the other.
Summary
This section has covered the steps to use a window to transform streaming data:
- Define the window using
Stream.batchandStream.last, for tumbling(unique) or sliding windows, respectively. - Defining a class or function that will perform your aggregation
- Use
Window.aggregate()to call your processing function with the window’s contents - For overlapping, or sliding windows, set the trigger policy with
Window.triggerto control when the processing function is called. - Use
Window.partitionto create subwindows for more fine grained aggregation.
Modifying data
You can invoke map or flat_map on a Stream object when you want to:
- Modify the contents of the tuple.
- Change the type of the tuple.
- Break one tuple into multiple tuples.
The following sections walk you through an example of each type of transform.
Map: Modifying the contents of a tuple
The Stream.map() function takes as input a callable object that takes a single tuple as an argument and returns either 0 or 1 tuple.
For example, you have a source function that returns a set of four words from the English dictionary. However, you want to create a Stream object that contains only the first four letters of each word. You need to use a map transform because it can modify the tuple.
To achieve this:
- Define a
Streamobject calledwordsthat is created by calling a function that generates a list of four words. (For simplicity, specify asourcefunction that returns only four words.) - Define a
mapfunction calledtransform_substring_functions.first_four_lettersthat transforms the tuples from thewordsStreaminto tuples that contain the first four letters from the original tuple. - Define a
sinkfunction that uses theprintfunction to write the tuples to output.
Include the following code in the transform_substring.py file:
from streamsx.topology.topology import Topology
import streamsx.topology.context
def words_in_dictionary():
return {"qualify", "quell", "quixotic", "quizzically"}
def first_four_letters(tuple):
return tuple[:4]
def main():
topo = Topology("map_substring")
words = topo.source(words_in_dictionary)
first_four_letters = words.map(first_four_letters)
first_four_letters.for_each(print)
streamsx.topology.context.submit("STANDALONE", topo)
if __name__ == '__main__':
main()
Sample output
Run the python3 transform_substring.py script.
The contents of your output look like this:
quix
quel
qual
quiz
As you can see, the map transform modifies the tuples. In this instance, the tuples are modified so that each tuple now only includes the first four letters of each word.
Map: Changing the type of a tuple
In this example, you have a Stream object of strings, and each string corresponds to an integer. You want to create a Stream object that uses the integers, rather than the strings, so that you can perform mathematical operations on the tuples.
To achieve this:
- Define a
Streamobject calledstring_tuplesthat is created by calling a function calledint_strings. Theint_stringsfunction returns a list of string values that are integer values. (For simplicity, specify asourcefunction that returns the following strings: “1”, “2”, “3”, “4’.) - Define a
mapfunction calledstring_to_intthat map the tuples from thestring_tuplesStreamobject into Pythonintobjects. - Define a
mapfunction calledmultiply2_add1that multiples eachintobject by 2 and adds one to the result. - Define a
sinkfunction that uses theprintfunction to write the tuples to output.
Include the following code in the transform_type.py file:
from streamsx.topology.topology import Topology
import streamsx.topology.context
def int_strings():
return ["1", "2", "3", "4"]
def string_to_int(tuple):
return int(tuple)
def multiply2_add1(tuple):
return (tuple * 2) + 1
def main():
topo = Topology("map_type")
string_tuples = topo.source(int_strings)
int_tuples = string_tuples.map(string_to_int)
int_tuples.map(multiply2_add1).for_each(print)
streamsx.topology.context.submit("STANDALONE", topo)
if __name__ == '__main__':
main()
Sample output
Run the python3 transform_type.py script.
The contents of your output look like this:
3
5
7
9
Tip: You can transform a Stream tuple to any Python object if the returned object’s class can be serialized by using the pickle module.
Additionally, you aren’t restricted to using built-in Python classes, such as string, integer, and float. You can define your own classes and pass objects of those classes as tuples on a Stream object.
Flat_map: Breaking one tuple into multiple tuples
The flat_map transform converts each incoming tuple from a Stream object into 0 or more tuples. The Stream.flat_map() function takes a single tuple as an argument, and returns an iterable of tuples.
For example, you have a Stream object in which each tuple is a line of text. You want to break down each tuple so that each resulting tuple contains only one word. The order of the words from the original tuple is maintained in the resulting Stream object.
- Define a
Streamobject calledlinesthat generates lines of text. - Split the
linesStreamobject into individual words by passing thesplitfunction into theflat_maptransform.
Sample application
To achieve this:
Include the following code in the multi_transform_lines.py file:
from streamsx.topology.topology import Topology
import streamsx.topology.context
def main():
topo = Topology("flat_map_lines")
lines = topo.source(["mary had a little lamb", "its fleece was white as snow"])
words = lines.flat_map(lambda t : t.split())
words.print()
streamsx.topology.context.submit("STANDALONE", topo)
if __name__ == '__main__':
main()
Sample output
Run the python3 multi_transform_lines.py script.
The contents of your output look like this:
mary
had
a
little
lamb
its
fleece
was
white
as
snow
As you can see, the flat_map transform broke each of the original tuples into the component pieces, in this case, the component words, and maintained the order of the pieces in the resulting tuples.
Tip: You can use the flat_map transform with any list of Python objects that is serializable with the pickle module. The members of the list can be different classes, such as strings and integers, user-defined classes, or classes provided by a third-party module.
—
Keeping track of state information across tuples
In the previous examples, you used stateless functions to manipulate the tuples on a Stream object. A stateless function does not keep track of any information about the tuples that have been processed, such as the number of tuples that have been received or the sum of all integers that have been processed.
By keeping track of state information, such as a count or a running total, you can create more useful applications.
A stateful function references data that is preserved across calls to the function.
You can define stateful data within the scope of a callable object. The data is local to the function. When the function exits, the data is no longer accessible.
For example, you have a Stream object of random numbers and you want to define a function that consumes the Stream object and keeps track of the moving average across the last ten tuples. You can define a list in the callable object to keep track of the tuples on the Stream object. The state of the list persists across calls to the function.
To achieve this:
Add the following code in the transform_stateful.py file:
from streamsx.topology.topology import Topology
import streamsx.topology.context
import random
def readings():
while True:
yield random.gauss(0.0, 1.0)
class AvgLastN:
def __init__(self, n):
self.n = n
self.last_n = []
def __call__(self, tuple):
self.last_n.append(tuple)
if (len(self.last_n) > self.n):
self.last_n.pop(0)
return sum(self.last_n) / len(self.last_n)
def main():
topo = Topology("transform_stateful")
floats = topo.source(readings)
avg = floats.map(AvgLastN(10))
avg.for_each(print)
streamsx.topology.context.submit("STANDALONE", topo)
if __name__ == '__main__':
main()
Sample output
Run the python3 transform_stateful.py script.
The contents of your output file looks something like this:
...
-0.129801183721193
-0.24261908760937825
-0.31236638019773516
-0.40426366430734334
-0.24643244932349337
-0.28186826075709115
...
In this example, AvgLastN.n, which is initialized from the user-defined parameter n, and AvgLastN.last_n are examples of data whose state is kept in between tuples.
Tip: Any type of transform (source, filter, map, and sink) can accept callable objects that maintain stateful data. —
You can also create a user-defined function that refers to global variables. Unlike variables that are defined within a function, global variables persist in the runtime process. However, this approach is not recommended because the way in which the processing elements are fused can change how global variables are shared across functions or callable objects.
For example, in stand-alone mode, there is a single copy of a global variable. This copy is shared by all of the functions that reference it. In distributed mode, multiple copies of a global variable might exist because the topology is distributed across multiple processing elements (processes). If any Python code on a processing element executes a function that references the global variable, the processing element will have its own copy of the global variable.
Splitting streams
You can split a stream into more than one output stream. By splitting a stream, you can perform different processing on the data depending on an attribute of a tuple. For example, you might want to perform different processing on log file messages depending on whether the message is a warning or an error.
You can split a stream by using any operator. Each time you call a function, such as filter, transform, or sink, the function produces one output stream. If you call a function on the same Stream object three times, it creates three output streams. The tuples from the input stream are distributed to all of the destination streams.
For example, the following code snippet splits the stream1 Stream object into two streams:
stream2 = stream1.filter(...)
stream3 = stream1.filter(...)
A visual representation of this code would look something like this:

The following example shows how you can distribute tuples from a source function to two sink functions. Each sink function receives a copy of the tuples from the source Stream object.
Sample application
Include the following code in the split_source.py file:
from streamsx.topology.topology import Topology
import streamsx.topology.context
def source_tuples():
return ["tuple1", "tuple2", "tuple3"]
def print1(tuple):
print("print1", tuple)
def print2(tuple):
print("print2", tuple)
def main():
topo = Topology("split_source")
source = topo.source(source_tuples)
source.for_each(print1)
source.for_each(print2)
streamsx.topology.context.submit("STANDALONE", topo)
if __name__ == '__main__':
main()
Sample output
Run the python3 split_source.py script.
The contents of your output file looks something like this:
...
print2 tuple1
print1 tuple1
print2 tuple2
print1 tuple2
print2 tuple3
print1 tuple3
Splitting to dedicated streams
Another option is to split tuples from a stream into multiple independent streams using the split method on a stream.
A visual representation of this code would look something like this:

The following example shows splitting a stream based upon message severity.
Each sink function receives routed tuples from the source Stream. The split category is given within the function applied to the split method.
Tuples from a source function are split to three streams, each stream representing a severity of the message.
Sample application
Include the following code in the split_func.py file:
from streamsx.topology.topology import Topology
import streamsx.topology.context
def read_messages():
return {"M-a-message", "L-another-message", "H-v-i-m", "L-any-message"}
def get_severity(tuple):
SEVS = {'H':0, 'M':1, 'L':2}
return SEVS.get(tuple[0])
def main():
topo = Topology("split-streams")
msgs = topo.source(read_messages)
severities = msgs.split(3, get_severity, names=['high','medium','low'], name='SeveritySplit')
high_severity = severities.high
high_severity.print(tag='HIGH')
medium_severity = severities.medium
medium_severity.print(tag='MEDIUM')
low_severity = severities.low
low_severity.print(tag='LOW')
streamsx.topology.context.submit("STANDALONE", topo)
if __name__ == '__main__':
main()
Sample output
Run the python3 split_func.py script.
The contents of your output looks something like this:
LOW: L-another message
HIGH: H-vim
LOW: L-any message
MEDIUM: M-a message
Reference
Joining streams (union)
You can combine multiple streams into a single Stream object by using the union transform. The Stream.union() function takes a set of streams as an input variable and combines them into a single Stream object. However, the order of the tuples in the output Stream object is not necessarily the same as in the input streams.
For example, you want to combine the streams from the source functions h, b, c, and w. You can combine the streams by using the union function and then use the sink function to write the resulting Stream object to output.
Sample application
To achieve this:
Include the following code in the union_source.py file:
from streamsx.topology.topology import Topology
import streamsx.topology.context
def hello() :
return ["Hello",]
def beautiful() :
return ["beautiful",]
def crazy() :
return ["crazy",]
def world() :
return ["World!",]
def print1(tuple):
print(" - ", tuple)
def main():
topo = Topology("union_source")
h = topo.source(hello)
b = topo.source(beautiful)
c = topo.source(crazy)
w = topo.source(world)
hwu = h.union({b, c, w})
hwu.for_each(print1)
streamsx.topology.context.submit("STANDALONE", topo)
if __name__ == '__main__':
main()
Sample output
Run the python3 union_source.py script.
The contents of your output file looks something like this:
...
- Hello
- beautiful
- crazy
- World!
Remember: The order of the tuples might be different in your output.
Publishing streams
You can make an output stream available to applications by using the publish transform. The Stream.publish() function takes the tuples on a stream, converts the tuples to Python objects, JSON objects, or strings, and then publishes the output to a topic. (A topic is based on the MQTT topic specification. For more information, see the MQTT protocol specification)
To receive the tuples, an application must subscribe to the topic that you publish by specifying the same topic and schema. For more information, see Subscribing to streams.
Restrictions: The publish transform does not work in STANDALONE mode. Additionally, the application that publishes and the one that subscribes must be running in the same instance of IBM Streams.
—
For example, you can use the publish transform to make tuples from a Python streams-processing application available to an IBM Streams Processing Language (SPL) streams-processing application.
The schema that you specify determines the type of objects that are published:
-
CommonSchema.Pythonpublishes the tuples on the stream as Python objects.This is the default schema.
-
CommonSchema.Jsonpublishes the tuples on the stream as JSON objects. Each tuple is converted to JSON by using thejson.dumpsfunction.JSON is a common interchange format between all languages that are supported by IBM Streams (SPL, Java, Scala, and Python).
Restriction: Each tuple object on the stream must be able to be converted to JSON. If the objects cannot be converted, an exception is thrown and the application fails.
-
CommonSchema.Stringpublishes the tuples on the stream as strings. Each tuple is converted to a string by using thestr()function.String is a common interchange format between all languages that are supported by IBM Streams (SPL, Java, Scala, and Python).
Sample code
The Stream.publish() function takes as input the name of the topic that you want to publish the tuples to and the schema to publish. The function returns None.
For example, you want to publish a stream of integers as JSON objects with the topic called simple so that another application in your instance can use the data.
To achieve this:
Include the following lines in the publish.py file:
from streamsx.topology.topology import *
from streamsx.topology.schema import *
import streamsx.topology.context
import itertools
import time
def sequence():
return itertools.count()
def delay(v):
time.sleep(0.1)
return True
def main():
topo = Topology("PublishSimple")
ts = topo.source(sequence)
ts = ts.filter(delay)
ts.publish('simple', CommonSchema.Json)
ts.print()
streamsx.topology.context.submit('DISTRIBUTED', topo)
if __name__ == '__main__':
main()
This example is based on the pubsub sample in GitHub. For more information about how this application works, see https://github.com/IBMStreams/streamsx.topology/tree/develop/samples/python/topology/pubsub
Subscribing to streams
If an application publishes a stream to a topic, you can use the subscribe transform to pull that data into your application.
Remember: The subscribe transform must be running in the same instance of IBM Streams as the application that is publishing data.
—
To subscribe to a topic, use the Topology.subscribe function, specifying the same topic and schema as the corresponding Topology.publish function. The application that published the topic can be written in any language that IBM Streams supports.
The schema determines the type of objects that the application receives:
-
CommonSchema.Pythonreceives tuples that have been published as Python objects.This is the default schema.
-
CommonSchema.Jsonreceives tuples that have been published as JSON objects. Each tuple on the stream is converted to a Python dictionary object by using thejson.loads(tuple)function. -
CommonSchema.Stringreceives tuples that have been published as strings. Each tuple on the stream is converted to a Python string object.
You can also subscribe to topics that use an SPL schema. (Most applications that publish a topic with an SPL schema are SPL applications. However, Java and Scala applications can also publish streams with an SPL schema.)
When you use the Topology.subscribe() function for a topic with an SPL schema in a Python application, the tuple attributes from the topic are converted to the appropriate Python type and added to a Python dictionary object. (The name of the attribute is used as the dictionary key value.)
The syntax that you use to subscribe to an SPL schema is schema.StreamSchema(“tuple<attribute_type attribute_name, ...>”). The schema must exactly match the schema that is specified by the corresponding publish transform. For example:
- A simple schema might be
schema.StreamSchema(“tuple<ustring ustr1>”) - A more complex schema might be
schema.StreamSchema(tuple“<rstring rs1, uint32 u321, list<uint32> liu321, set<uint32> setu321>")
Python supports the following SPL attribute types:
| SPL attribute type | Resulting Python type | Notes |
|---|---|---|
| int8, int16, int36, or int64 | int | |
| uint8, uint16, uint36, or uint64 | int | The uint64 type can’t be published to JSON if the value is bigger than Long.MAX_VALUE. |
| float32 or float64 | float | |
| complex32 or complex64 | complex | The complex32 and complex64 types can’t be published to JSON. |
| rstring | str | |
| ustring | str | |
| boolean | boolean | |
| list | list | |
| map | dictionary | |
| set | set | The set type can’t be published to JSON. |
Sample code
The Topology.subscribe() function takes as input the name of the topic that you want to subscribe to and the schema describing the stream. The function returns a Stream object whose tuples have been published to the topic by an IBM Streams application.
For example, you want to subscribe to the stream that you published in Publishing streams.
To achieve this, include the following lines in the subscribe.py file:
from streamsx.topology.topology import *
import streamsx.topology.context
def main():
topo = Topology("SubscribeSimple")
ts = topo.subscribe('simple', schema.CommonSchema.Json)
ts.print()
streamsx.topology.context.submit("DISTRIBUTED", topo)
if __name__ == '__main__':
main()
Sample output
Run the python3 subscribe.py script.
The contents of your output file look something like this:
...
12390
12391
12392
12393
12394
12395
...
For more information, see Publish-subscribe overview.
Defining a stream’s schema
A stream represents an unbounded flow of tuples with a declared schema so that each tuple on the stream complies with the schema.
A stream’s schema may be one of:
- StreamsSchema structured schema - a tuple is a sequence of attributes, and an attribute is a named value of a specific type.
- Json - a tuple is a JSON object.
- String - a tuple is a string.
- Python - a tuple is any Python object, effectively an untyped stream.
The application below uses the Stream.map() callable between a data source and data sink callable:

The diagram contains labels for stream1, stream2 and outputSchema since they are used in the code block and table below. Each SPL operator output port and corresponding stream are defined by a schema. In a Python toplogy application the CommonSchema.Python is the default schema for Python operators.
In this sample the output schema is defined with the schema parameter of the map() function.
outputSchema = CommonSchema.Python
stream2 = stream1.map(lambda t:t, schema=outputSchema)
The table below contains examples of the schema definition and the corresponding SPL schema that is generated by “streamsx.topology” when creating the application.
| Schema type | Schema in Python | Schema in generated SPL |
|---|---|---|
| Python | outputSchema = CommonSchema.Python |
tuple<blob __spl_po> |
| String | outputSchema = CommonSchema.String |
tuple<rstring string> |
| Json | outputSchema = CommonSchema.Json |
tuple<rstring jsonString> |
| StreamsSchema | outputSchema = 'tuple<int64 intAttribute, rstring strAttribute>' |
tuple<int64 intAttribute, rstring strAttribute> |
So far, schemas are not used explicitly in this guide. But in a large application it is good design to define structured schema(s).
And in certain cases, you must have a schema different than CommonSchema.Python:
- when writing an application using different kinds of callables (Streams SPL operators), because the Python schema is not supported in SPL Java primitive and SPL C++ primitive operators.
- when using publish and subscribe between different applications (if one application is not using Python operators)
- when creating a job as service endpoint to consume/produce data via REST using EndpointSink or EndpointSource streamsx.service
Structured Schema
Structured schema can be declared a number of ways:
- An instance of
typing.NamedTuple - An instance of
StreamSchema - A string of the format
tuple<...>defining the attribute names and types. - A string containing a namespace qualified SPL stream type (e.g.
com.ibm.streams.geospatial::FlightPathEncounterTypes.Observation3D)
Structured schemas provide type-safety and efficient network serialization when compared to passing a dict using Python streams.
Topology.source()
- No support of explicit schema definition
- Generates CommonSchema.Python by default
- Use type hint at the “source” callable to generate a structured schema stream
In the sample below, the type hint -> Iterable[SampleSourceSchema] is added to the __call__(self) method in the class used as callable in your source.
The structured schema SampleSourceSchema is defined a named tuple.
from streamsx.topology.topology import Topology
import streamsx.topology.context
from typing import Iterable, NamedTuple
import itertools, random
class SampleSourceSchema(NamedTuple):
id: str
num: int
# Callable of the Source
class SampleSource(object):
def __call__(self) -> Iterable[SampleSourceSchema]:
for num in itertools.count(1):
yield {"id": str(num), "num" : random.randint(0,num)}
topo = Topology("sample-source-structured-stream")
src = topo.source(SampleSource())
src.print()
streamsx.topology.context.submit("STANDALONE", topo)
Structured schema passing styles (dict vs. named tuple)
In the former example the source callable returned a dict. You can also return named tuple objects and in both cases the downstream callable tuples are passed in named tuple style.
from streamsx.topology.topology import Topology
import streamsx.topology.context
from typing import Iterable, NamedTuple
import itertools, random
class SampleSourceSchema(NamedTuple):
id: str
num: int
# Callable of the Source
class SampleSource(object):
def __call__(self) -> Iterable[SampleSourceSchema]:
for num in itertools.count(1):
output_event = SampleSourceSchema(
id = str(num),
num = random.randint(0,num)
)
yield output_event
class SampleMapSchema(NamedTuple):
idx: str
number: int
def map_namedtuple_to_namedtuple(tpl) -> SampleMapSchema:
out = SampleMapSchema(
idx = 'x-' + tpl.id,
number = tpl.num + 1
)
return out
topo = Topology("sample-namedtuple-structured-stream1")
stream1 = topo.source(SampleSource())
stream2 = stream1.map(map_namedtuple_to_namedtuple)
stream2.print()
streamsx.topology.context.submit("STANDALONE", topo)
Does a type hint replace the use of specifying the schema parameter when calling the map transform?
If schema is set, then the return type is defined by the schema parameter. Otherwise if schema is not set then the return type hint on func define the schema of the returned stream, defaulting to CommonSchema.Python if no type hints are present.
Find below the same sample using dict style in “source” callable, but the type hint with named tuple schema causes that tuples are passed in named tuple style to map() callable.
from streamsx.topology.topology import Topology
import streamsx.topology.context
from typing import Iterable, NamedTuple
import itertools, random
class SampleSourceSchema(NamedTuple):
id: str
num: int
# Callable of the Source
class SampleSource(object):
def __call__(self) -> Iterable[SampleSourceSchema]:
for num in itertools.count(1):
yield {"id": str(num), "num" : random.randint(0,num)}
class SampleMapSchema(NamedTuple):
idx: str
number: int
def map_namedtuple_to_namedtuple(tpl) -> SampleMapSchema:
out = SampleMapSchema(
idx = 'x-' + tpl.id,
number = tpl.num + 1
)
return out
topo = Topology("sample-namedtuple-structured-stream2")
stream1 = topo.source(SampleSource())
stream2 = stream1.map(map_namedtuple_to_namedtuple)
stream2.print()
streamsx.topology.context.submit("STANDALONE", topo)
The following samples uses a SPL operator streamsx.standard.utility.Sequence generating a structured schema streamsx.standard.utility.SEQUENCE_SCHEMA
Here you see the difference to the previous sample, that the tuples are passed to the Python callable in dict style (see Delta() class used in streams1.map(Delta()). Furthermore this sample demonstrates how to extend a structured schema with streamsx.topology.schema.StreamSchema.extend function. In the map() callable the new attribute d is set.
from streamsx.topology.topology import Topology
import streamsx.topology.context
from typing import Iterable, NamedTuple
import streamsx.standard.utility as U
from streamsx.topology.schema import StreamSchema
class Delta(object):
def __init__(self):
self._last = None
def __call__(self, v):
if v['seq'] == 0:
self._last = v['ts']
return None
else:
v['d'] = v['ts'].time() - self._last.time()
return v
topo = Topology("sample-dict-structured-stream")
stream1 = topo.source(U.Sequence(iterations=50, period=0.2)) # output schema: tuple<uint64 seq, timestamp ts>
E = U.SEQUENCE_SCHEMA.extend(StreamSchema('tuple<float64 d>'))
stream2 = stream1.map(Delta(), schema=E) # output schema: tuple<uint64 seq, timestamp ts, float64 d>
stream2.print()
streamsx.topology.context.submit("STANDALONE", topo)
Summary:
- Passing style (dict/named tuple) in your callable depends on the predecessor callable/operator.
- When named tuple schema is defined in predecessor callable/operator, then expect passing style named tuple in your Python callable.
- Use either name tuple schema or StreamsSchema between SPL operators and Python callables.