Create your first application
Edit meThis tutorial demonstrates creating a Streams Python application to perform some analytics, and viewing the results.
Familiarity with Python is recommended.
Prerequisites
Follow the steps in the previous section to install the Python API and set up your development environment.
Download this tutorial
-
As a notebook:
If you have Cloud Pak for Data as a Service (CPDaaS), IBM Cloud Pak for Data, or Jupyter notebooks installed, this tutorial is available as a notebook. Click the link below, and then click Save Page in your browser to save the notebook.
Overview
This tutorial demonstrates creating a Streams Python application to perform some analytics, and viewing the results.
The application simulates a data hub that receives readings from sensors. It computes the 30 second rolling average of the reported readings using Pandas.
Video walkthrough
If you are not ready to run the tutorial, this video is a walkthrough of creating and running the application in IBM Cloud Pak for Data 3.5.
Streams Python application basics
A Streams Python application processes a continuous and potentially infinite stream of data. The data is processed in memory and is not stored in a database first.
A Streams application is a directed flow graph of data called a Topology. Data is ingested and then processed using transforms, which are either built-in or user-defined functions.
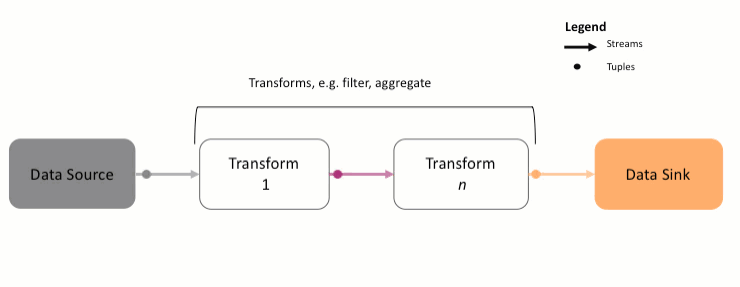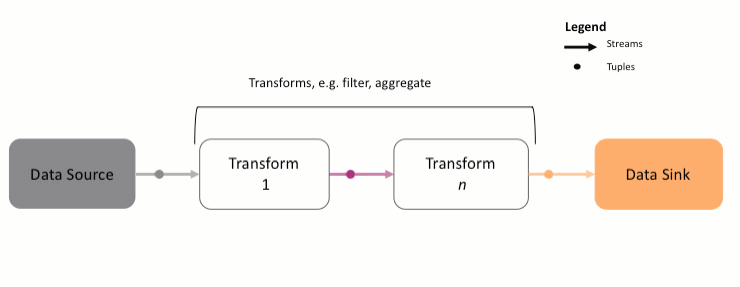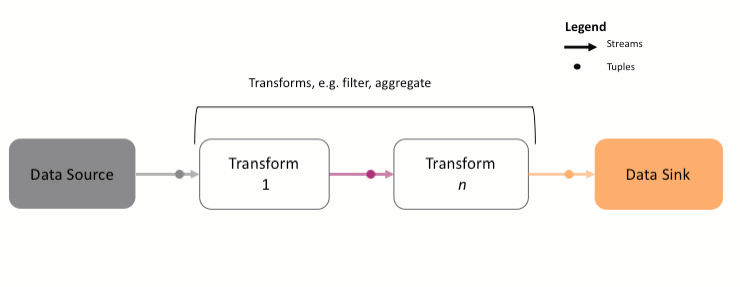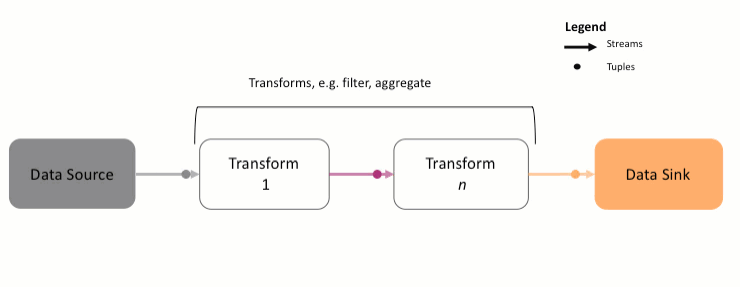
There are 2 basic steps to creating and running a Topology.
First, you define the Topology by describing how the application will ingest and process data.
Once you define the Topology, you submit it for execution. This means that the Topology will be converted into a runnable Streams application and (typically, but not always) sent to the Streams instance for execution.
As the subsequent animation shows, when you submit a Topology, the Topology will not run directly on your local host, but on the Streams runtime you specify.
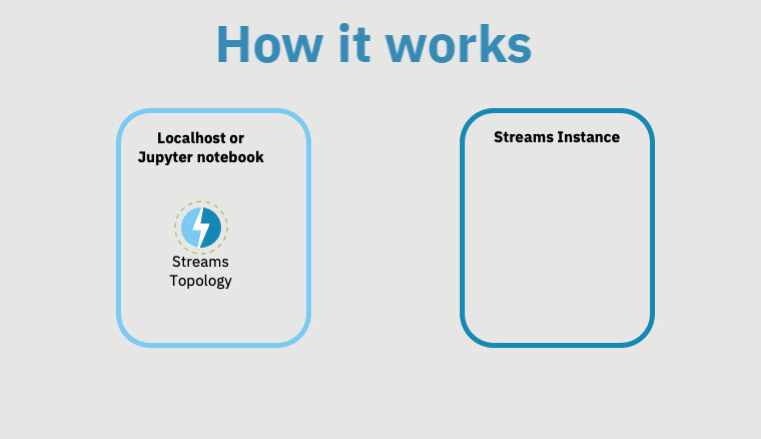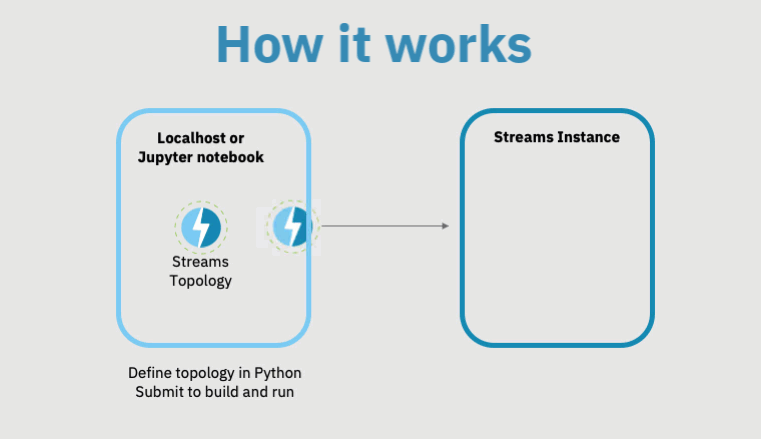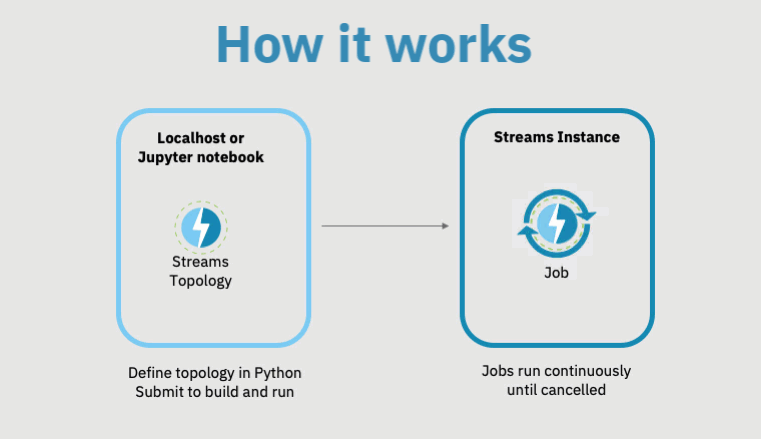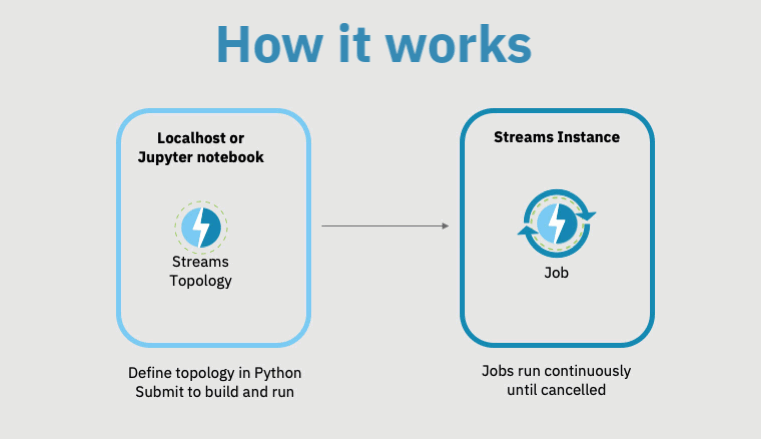
Once the application is running on the Streams instance, you can connect to it to continuously retrieve the results.
To summarize:
- A Streams Python application is called a
Topology. - You define a
Topologyby specifying how it will process a stream of data - The
Topologyis submitted to the Streams instance for execution.
1. Set up a connection to the Streams instance
To run a Topology, you submit it programmatically to the Streams instance.
See the submit_topology function from the previous section.
2. Create the application
All Streams applications start with a Topology object, so start by creating one:
from streamsx.topology.topology import Topology
topo = Topology(name="SensorAverages", namespace="sample")
2.1 Define sources
Your application needs some data to analyze, so the first step is to define a data source that produces the data to be analyzed.
Next, use the data source to create a Stream object. A Stream is a potentially infinite sequence of tuples containing the data to be analyzed.
A tuple can be any Python object. However, it is recommended to use NamedTuples to describe a tuple’s attributes.
See the doc for all supported formats.
2.1.1 Define a source class
The following cell defines the schema for the data to be analyzed, and a callable class that will produce the data.
This example class called SensorReadingSource generates a Stream of readings from sensors. Each tuple on the Stream is an instance of the SensorReading class.
import random
import time
from datetime import datetime, timedelta
from typing import Iterable, NamedTuple
## Define the schema of the tuples
# each tuple will have a value, sensor id and timestamp
class SensorReading(NamedTuple):
sensor_id: str
value: float
ts: int
# Define a callable source
class SensorReadingsSource(object):
# function that generates the data
# notice the type hint is an Iterable of the schema
def __call__(self) -> Iterable[SensorReading]:
# This is just an example of using generated data,
# Here you could connect to db
# generate data
# connect to data set
# open file
while True:
time.sleep(0.001)
random_id = random.randint(1,100)
sensor_id = "sensor_" + str(random_id)
value = random.random() * 3000
ts = int((datetime.now().timestamp()))
yield SensorReading(sensor_id, value, ts)
2.1.2 Create a source Stream
A Topology always begins creating a source Stream that contains the data you want to process.
Create a Stream called readings that will contain the simulated data from the SensorReadingsSource class:
# Create a stream from the data using Topology.source
readings = topo.source(SensorReadingsSource(), name="Readings")
2.2 Analyze data
Use a variety of methods in the Stream class to analyze your in-flight data, including applying machine learning models.
This application will:
- Filter out tuples based on a condition
- Compute the rolling average
- Enrich the rolling average with data from another source
Built-in methods exist for common operations, such as
Stream.filter and Stream.split, which filter or split a stream of data respectively.
See the common operations section for other common examples. Check out the documentation of the Stream class for full list of functions.
2.2.1 Filter data from the Stream
Use Stream.filter() to remove data that doesn’t match a certain condition.
# Accept only values greater than 100
valid_readings = readings.filter(lambda x : x.value > 100,
name="ValidReadings")
# You could create another stream of the invalid data:
# invalid_readings = readings.filter(lambda x : x.value <= 100)
2.2.2 Compute averages on the Stream
Define a function to compute the 30 second rolling average for the readings.
See the numbered steps in the code below.
import pandas as pd
# 1. Define schema of aggregation result
class AverageReadings(NamedTuple):
average: float
sensor_id: str
period_end: str
# 2. Define aggregation function, note type hint
# this function returns a list of averages
# one for each sensor
def average_reading(items_in_window) -> Iterable[AverageReadings]:
df = pd.DataFrame(items_in_window)
readings_by_id = df.groupby("sensor_id")
averages = readings_by_id["value"].mean()
period_end = df["ts"].max()
result = []
for id, avg in averages.iteritems():
result.append(AverageReadings(avg, id, time.ctime(period_end)))
return result
# 3. Define window: e.g. a 30 second rolling average, updated every second
interval = timedelta(seconds=30)
window = valid_readings.last(size=interval).trigger(when=timedelta(seconds=1))
# 3. Pass aggregation function to Window.aggregate
# average_reading returns a list of the averages for each sensor,
# use flat map to convert it to individual tuples, one per sensor
rolling_average = window.aggregate(average_reading).flat_map()
A
Window is a subset of the potentially infinite data on a Stream. When you use a Window to process a subset of your data, the data is not stored on disk or in a database, but is processed in memory.
2.2.3 Enrich the data on the Stream
Each tuple on the rolling_average Stream will have the following format:
{'average': 1655.1009278955999, 'sensor_id': 'sensor_17', 'period_end': 'Tue Nov 19 22:07:02 2019'}
. (See the average_reading function above).
Imagine that you want to add the geographical coordinates of the sensor to each tuple. This information might come from a different data source, such as a database.
Use Stream.map(). The map transform uses a function you provide to convert each tuple on the Stream into a new tuple.
In our case, for each tuple on the rolling_average Stream, we will update it to include the geographical coordinates of the sensor. The tuples produced by the enrich function will have a new schema, AverageWithLocation, which extends the AverageReadings schema.
class AverageWithLocation(NamedTuple):
average: float
sensor_id: str
period_end: str
latitude: float
longitude: float
# Modify this tuple with the coordinates of the sensor
# Returns the original tuple with a new coords attribute
# representing the latitude and longitude of the sensor
def enrich(tpl) -> AverageWithLocation:
# use simulated data, but you could make a database call,
latitude = round(random.random() + 39.8338515, 4)
longitude = round(-74.871826 + random.random(), 4)
# update the tuple with new data
enriched_tpl = AverageWithLocation(*tpl, latitude, longitude)
return enriched_tpl
# Update the data on the rolling_average stream with the map transform
enriched_average = rolling_average.map(enrich, schema=AverageWithLocation)
2.3 Create a View to preview the tuples on the Stream
A View is a connection to a Stream that becomes activated when the application is running. The connection allows you to access the data on the Stream as it is being processed.
After submitting the Topology, we use a View to examine the data in section 4.
To view the data on the enriched_average Stream, define a View using Stream.view():
averages_view = enriched_average.view(name="RollingAverage", description="Sample of rolling averages for each sensor")
You can connect to a view in any running Streams job using the REST API , regardless of what language was used to create the application.
2.4 Define output
You have several options for defining the output of your Streams application.
You could:
- Print the contents of a
Streamto the application logs. - Enable a microservices based architecture by publishing the contents of a
Stream. Other Streams applications can connect to the publishedStream. - Send the stream to another database or system.
- Create a REST service for the Streams application that will make data available via HTTP requests. (Cloud Pak for Data 3.5+ only).
This sample will:
- Use
Stream.publish()to make theenriched_average Streamavailable to other applications - Create a REST endpoint.
import json
# publish results as JSON
enriched_average.publish(topic="AverageReadings",
schema=json,
name="PublishAverage")
# Other options include:
# invoke another sink function:
# rolling_average.for_each(func=send_to_db)
# print the data: enriched_average.print()
2.5 (Optional) Create a REST service to access the data
Skip this step if you are not using Cloud Pak for Data 3.5 or newer.
In Cloud Pak for Data (CPD) version 3.5+, you can add a REST endpoint to a Streams application so that you can connect to it to retrieve tuples from a Stream.
How does it work?
- First, use
Stream.for_eachto send every tuple on the targetStreamto an instance of theEndpointSinkclass. - The
EndpointSinkclass creates a new service in the Cloud Pak for Data instance. - When the service receives a HTTP
GETrequest, it will respond with the tuples on theStream.
Run the following code if you are using CPD 3.5 or newer.
from streamsx.service import EndpointSink
# send each tuple on the enriched_average stream to the EndpointSink operator
# this operator will create a REST endpoint that you can use to access the data from the stream.
enriched_average.for_each(EndpointSink(), name="REST Service")
3. Submit the application
A running Streams application is called a job. Use this code to submit the Topology for execution, using the submit_topology function defined in step 1.
# The submission_result object contains information about the running application, or job
print("Submitting topology to Streams for execution...")
submission_result = submit_topology(topo)
if submission_result.job:
streams_job = submission_result.job
print ("Job ID: ", streams_job.id , "\nJob name: ", streams_job.name)
else:
print("Submission failed: " + str(submission_result))
4. Use a View to access data from the job
Now that the job is started, use the averages_view object you created in step 2.3 to start retrieving data from the enriched_average Stream.
# Connect to the view and display the data
print("Fetching view data...")
queue = averages_view.start_data_fetch()
try:
for val in range(10):
print(queue.get(timeout=60))
finally:
averages_view.stop_data_fetch()
4.0.1 Run the application
If you are using a notebook, the application should have been submitted when you ran step 3. Otherwise, if you are using the Python interpreter, running the above code should produce output like this:
JobId: 7
Job name: sample::SensorAverages_7
{'average': 1623.4117399203453, 'latitude': 40.1713, 'longitude': -73.9916, 'period_end': 'Mon Jan 18 21:58:13 2021', 'sensor_id': 'sensor_1'}
{'average': 1524.975990123786, 'latitude': 40.8136, 'longitude': -74.0563, 'period_end': 'Mon Jan 18 21:58:13 2021', 'sensor_id': 'sensor_10'}
{'average': 1490.6267900345765, 'latitude': 40.6964, 'longitude': -74.4742, 'period_end': 'Mon Jan 18 21:58:13 2021', 'sensor_id': 'sensor_100'}
{'average': 1572.332897576422, 'latitude': 40.256, 'longitude': -74.7667, 'period_end': 'Mon Jan 18 21:58:13 2021', 'sensor_id': 'sensor_11'}
{'average': 1578.6578550390263, 'latitude': 40.5148, 'longitude': -74.4141, 'period_end': 'Mon Jan 18 21:58:13 2021', 'sensor_id': 'sensor_12'}
{'average': 1574.873196796899, 'latitude': 40.3255, 'longitude': -74.0681, 'period_end': 'Mon Jan 18 21:58:13 2021', 'sensor_id': 'sensor_13'}
{'average': 1588.6722650277177, 'latitude': 40.6826, 'longitude': -74.1985, 'period_end': 'Mon Jan 18 21:58:13 2021', 'sensor_id': 'sensor_14'}
4.1 (Optional) Display the results in real time
Note: This code only works in a notebook that has ipywidgets enabled.
Calling View.display() from the notebook displays the results of the view in a table that is updated in real-time.
# Display the results for 30 seconds
averages_view.display(duration=30)
4.2 See job status
Streams applications can be monitored using the Job Graph or the Streams Console. The tool you'll use depends on your development environment and/or preference. The Job Graph is only available in Cloud Pak for Data, but the Streams Console is included with all versions of Streams.
Using the Job Graph
The Job Graph is available in the CPD web interface
For the Job Graph in CPD, see this section.
Using the Streams Console
If you are not using Streams in CPD or are looking for a more advanced alternative to the Job Graph, you can monitor the health of your Streams application and cluster using the Streams Console.
4.3 (Optional) Access the streaming data via REST
If you enabled the REST service in section 2.5, you will now have a service in your Cloud Pak for Data instance that you can use to retrieve the data from the application.
You will need the job id, which was printed in section 3 when you submitted the job and the name of the deployment space for your Cloud Pak for Data instance. Follow these steps to find the endpoint and use it.
5. Cancel the job
Streams jobs run indefinitely, so make sure you cancel the job once you are finished running the sample.
If you are using a notebook, run this line:
if submission_result.job.cancel():
print("Successfully cancelled the job")
Otherwise, cancel the job from Streams Console or the Job Graph.
Cancel the job from the Streams Console:
- Click the Cancel Job button in the toolbar.
- Select the job.
- Click Cancel.
Cancel the job from the Job Graph:
With the Job Graph open, right click anywhere and select Delete job. </li>
Summary
We started with a Stream called readings, which contained the data we wanted to analyze. Next, we used functions in the Stream object to perform simple analysis and produced the enriched_average stream. This stream is published for other applications running within our Streams instance to access.
After submitting the application to the Streams service, we used the enriched_average view to see the results.
Next Steps
-
Find more samples: There are several sample notebooks available in the starter notebooks repository on GitHub. Visit the repository for examples of how to connect to common data sources, including Apache Kafka, IBM, and Db2 Warehouse.
-
Learn more about how to use the API from the common Streams transforms section.