SPSS Analytics Toolkit Tutorial
Edit meOverview
Streams is a platform that enables real-time analytics of data in motion. The IBM SPSS family of products provides the ability to build predictive analytic models. The IBM SPSS Analytics Toolkit is for Streams developers who need to leverage the powerful predictive models in a real-time scoring environment. In this lab, you will be building Streams applications to use a predictive model to analyze cell characteristics from patients who are believed to be at risk of developing cancer.
The SPSS Analytics Toolkit
The SPSS Analytics Toolkit (com.ibm.spss.streams.analytics) contains Streams operators that integrate with IBM SPSS Modeler and SPSS Collaboration and Deployment Services products to implement various aspects of SPSS Modeler predictive analytics in your Streams applications. The SPSS Analytics Toolkit is installed by the SPSS Modeler Solution Publisher product, which is shipped by SPSS Collaboration and Deployment Services release 5.0 and later.
This lab was developed using Streams 4.0.1 and SPSS Modeler Solution Publisher version 17, however, older versions of both products that are compatible with each other should work for this lab.
The following operators are available in the SPSS Analytics Toolkits:
- SPSSScoring operator – integrates with SPSS Modeler Solution Publisher to enable the scoring of your SPSS Modeler -designed predictive models in Streams applications
- SPSSPublish operator – automates the ‘publish’ of a Modeler file’s scoring branch and summarizes the generated files so down-stream operators can refresh their scoring implementation with the PIM, PAR and XML files created or updated by the ‘publish’ operation
- SPSSRepository operator – detects notification events indicating changes to the deployed models managed in the SPSS Collaboration and Deployment Services repository and retrieves the indicated Modeler file version for automated publish and preparation for use in your Streams applications
Data
In this lab you will be working with a dataset containing characteristics of a number of human cell samples extracted from patients who were believed to be at risk of developing cancer.
Analysis of the original data showed that many of the characteristics differed significantly between benign and malignant samples. A Support Vector Machine (SVM) model was developed that can use the values of the these cell characteristics in samples from other patients to give an early indication of whether their samples might be benign or malignant.
The predictive Analytic Models are built using the IBM SPSS Modeler product. The models used in the Streams application have already been developed and are available for download here: SPSSModels.zip.
Exercise 1 uses a data set of patient data located in the Exercise1 project’s data directory named “cell_samples.data”.
Exercise 2 will use a Beacon operator to generate sample data.
The example is based on a dataset that is publicly available from the UCI Machine Learning Repository (Asuncion and Newman, 2007). The dataset consists of several hundred human cell sample records, each of which contains the values of a set of cell characteristics. The fields in each record are:
| Field Name | Description |
| ID | Patient Identifier |
| Clump | Clump thickness |
| UnifSize | Uniformity of cell size |
| UnifShape | Uniformity of cell shape |
| MargAdh | Marginal adhesion |
| SingEpiSize | Single epithelial cell size |
| BareNuc | Bare nucleoli |
| BlandChrom | Bland chromatin |
| NormNucl | Normal nucleoli |
| Mit | Mitoses |
| Class | Benign or malignant |
Downloads
SPSSModels.zip – Contains the SPSS model files used throughout the lab
SPSS_SPLProjects.zip – Contains the SPL Projects used in the exercises as well as the solution projects
Setup for the Lab
- Ensure that the SPSS Modeler Solution Publisher product is installed (included in SPSS Collaboration and Deployment Services 5.0 or later)
- See http://www-01.ibm.com/software/analytics/spss/ for more information
- Extract SPSSModels.zip into your home directory
- Import SPSS_SPLProjects.zip into Streams Studio
- In Streams Studio, use Streams Explorer to add the com.ibm.spss.streams.analytics toolkit, which comes packaged with SPSS Modeler Solution Publisher
-
In the instance you are going to submit your applications to, add the
CLEMRUNTIMEenvironment variable (it points to your SPSS Publisher installation):streamtool setproperty --application-ev -i CLEMRUNTIME=/path/to/spss_publisher/install
Exercise 1 – Produce a prediction and confidence for each cell sample in a file
Problem Statement
In this lab, use the SPSSScoring operator to calculate a prediction (benign=2 or malignant=4) and a confidence 0-100% based on cell sample data read from a file. Start with the Exercise1 code. It already contains the schema definition of the incoming data, the FileSource to read that data, a Functor that simulates the prediction and a FileSink to write out the predicted values. Your task is to replace the Functor with the SPSSScoring operator. There is a completed version in the Exercise1Solution project.
Outline
As a challenge, feel free to use this outline rather than the step by step instructions to build the application. If you get stuck, the completed exercise is in the Exercise1Solution project.
-
Create a new SPSSScoring operator.
-
Specify the pimfile, parfile and xmlfile parameters on the operator to point to the SPSS published model artifacts for model svm_cancer-goodrbf in the directory where you extract SPSSmodels.zip.
-
Specify the modelFields and streamsAttributes parameters that provide the necessary mapping from the streams tuple attributes to the model inputs. Hint: look in the SPSS published model xml file in the
tags to find the parameter names and datatypes needed by the SPSS model. -
Specify the output section to populate the prediction and confidence output tuple attributes from the model execution result. Hint: look in the SPSS published model xml file in the
tags to find the parameter names and datatypes produced by the SPSS model.
Step By Step Instructions
-
Right-click one the Excercise1 project. Select “Configure SPL Build.” Open the “SPL Build” twistie and click on “Environment.” Add the
CLEMRUNTIMEandSPSS_TOOLKIT_INSTALLenvironment variables.CLEMRUNTIME /path/to/spss_publisher/install SPSS_TOOLKIT_INSTALL /path/to/com.ibm.spss.streams.analytics
-
Open the Exercise1 project twistie, and right click on the
Exercise1main composite. Select “Open with Graphical Editor“. -
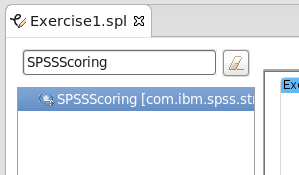
In the Graphical Editor, search for the SPSSScoring operator by typing it in the text box above the palette on the right side.
-
Drag the SPSSScoring operator from the palette and drop it onto the Functor operator in the middle of the graph.
Note: This technique allows you to replace an operator with a different one. The editor will handle refactoring.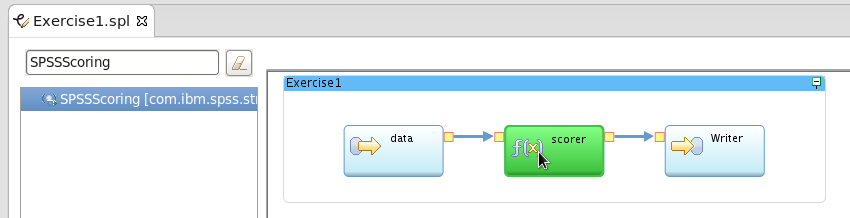
-
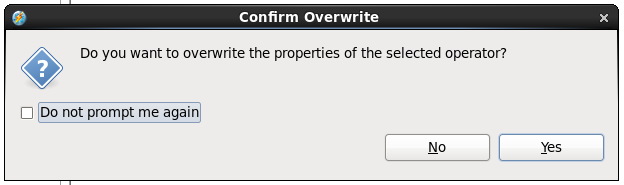
Select ‘Yes’ when prompted to override the selected operator.
-
Right-click on the SPSSScoring operator and select ‘Edit’
-
In the Properties view that opens, click on the Param tab.
-
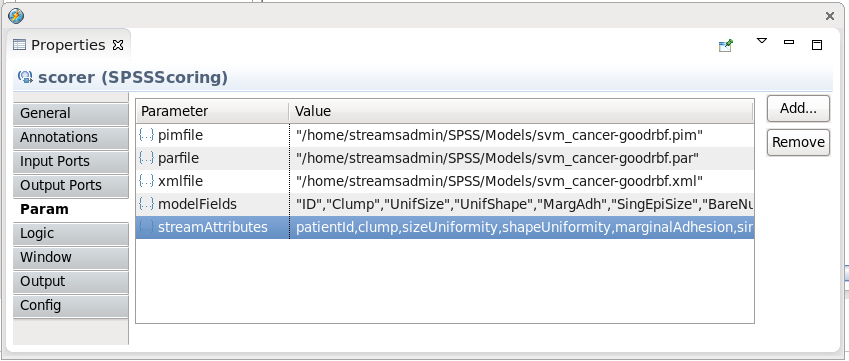
Update each of the parameters with the following values:
pimfile: "/home/streamsadmin/SPSS/Models/svm_cancer-goodrbf.pim" parfile: "/home/streamsadmin/SPSS/Models/svm_cancer-goodrbf.par" xmlfile: "/home/streamsadmin/SPSS/Models/svm_cancer-goodrbf.xml" modelFields: "ID","Clump","UnifSize","UnifShape","MargAdh","SingEpiSize","BareNuc","BlandChrom","NormNucl","Mit","Class" streamAttributes: patientId,clump,sizeUniformity,shapeUniformity,marginalAdhesion,singEpiSize,bareNucleoli,blandChromatin,normalNucleoli,mitoses,actualClassNote: You can use the above to copy and paste into the Studio parameters page. When finished the values should match the ones below.
- In the Properties view, click on the Output tab
-
Expand the tree items and update the ‘prediction’ and ‘confidence’ attributes with the following values:
prediction: fromModel(“SClass”) confidence: fromModel(“SPClass”)
Note: You can use the above to copy and paste into the Studio parameters page. When finished the values should match the ones below.
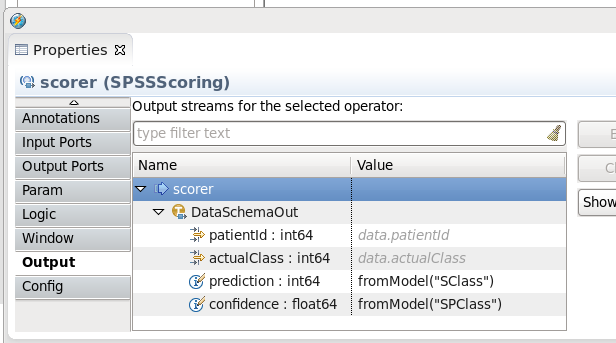
- Save the changed file. The project will auto-compile for you. Fix any errors.
Run
Run the distributed build for the Exercise1 main composite.
The output will be written to the output.txt file in the projects data directory and should look like:
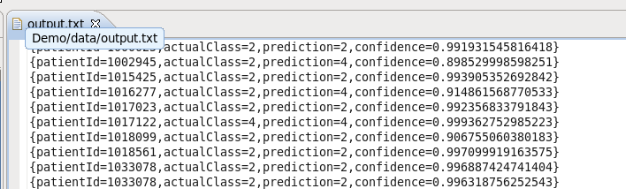
Exercise 2 – Dynamic model refresh
Problem Statement
In Exercise 1, some patient records were not being predicted correctly. The correct this error, we will need to use a different SPSS model. In Exercise 2, we will demonstrate how a model can be dynamically replaced without stopping the streams application. We will update the model to replace the default function, called the Radial Basis Function or RBF, will another function called the Polynomial function. After dynamically updating the model, we will observe that the patient record gets predicated correctly.
Start with the Exercise2 code. It contains the schema definition of the incoming data, a Beacon operator to simulate incoming data, a SPSSScoring operator that uses the current RBF model and Custom operator that uses print statements to show the scoring output. The Beacon operator will produce a single patient record that the default function (RBF) does not correctly predict. In the steps that follow, you will implement the SPSSPublish operator and attach it to the SPSSScoring operator in order to trigger a model refresh.
Goal
Your goal is to add the com.ibm.spss.streams.analytics::SPSSPublish operator to accept a new model.str model file, create the published artifacts (pim, par, xml files) and pass the new pim file location to the optional input port on the SPSSScoring operator. You should use a DirectoryScan operator to feed the SPSSPublish operator with a new model.str file.
Outline
- Add a DirectoryScan operator to “watch” the
DynamicModelsdirectory found within the directory where you extracted SPSSmodels.zip (for example “/home/streamsadmin/SPSS/Models/DynamicModels“) - Add a SPSSPublish operator to take model.str files and produce the published artifacts and feed the file name to the SPSSScoring operator.
- Modify the SPSSScoring operator to accept the additional optional input port data.
You should start with Exercise2. There is a completed version in the Exercise2Solution project.
Step By Step Instructions
-
Right-click on the Excercise2 project. Select “Configure SPL Build.” Open the “SPL Build” twistie and click on “Environment.” Add the
CLEMRUNTIMEandSPSS_TOOLKIT_INSTALLenvironment variables.CLEMRUNTIME /path/to/spss_publisher/install SPSS_TOOLKIT_INSTALL /path/to/spss_toolkit/install - Open the Exercise2 project twistie, and right click on the
Exercise2main composite. Select “Open with Graphical Editor” - In the palette, type “DirectoryScan” to search for the DirectoryScan operator
- Add the DirectoryScan operator to the graph by dragging it onto the
Exercise2composite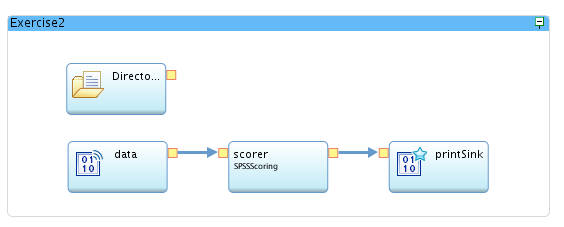
- Right-click on the DirectoryScan operator and select Edit to open the Properties view
-
Select the Output Ports tab and update the Output stream schema with the following:
Name: strFilepath Type: rstringNote: You can use the above to copy and paste into the Studio parameters page. When finished the values should match the ones below.
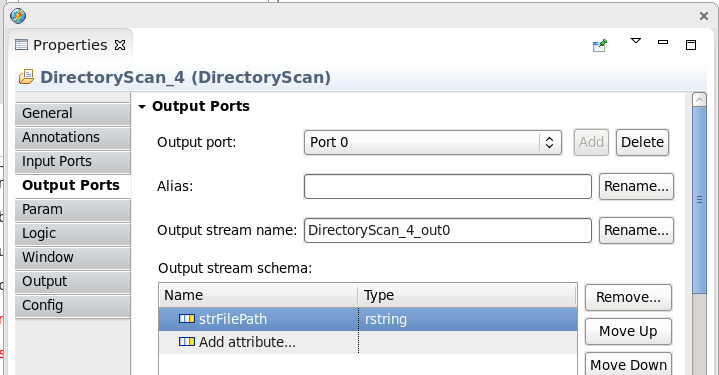
-
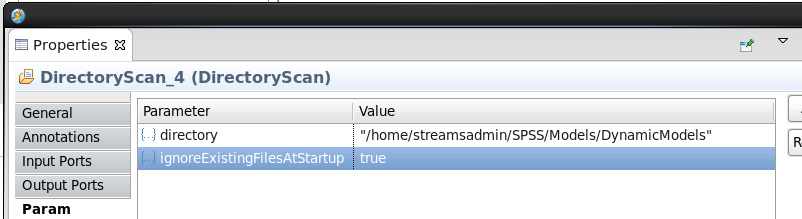
In the Properties view, click on the Param tab and set the following parameters (you will need to update the path to point to the location where you extracted the SPSSModels.zip file):
directory "/home/streamsadmin/SPSS/Models/DynamicModels" ignoreExistingFilesAtStartup: trueNote: You can use the above to copy and paste into the Studio parameters page. When finished the values should match the ones below.
- Add the SPSSPublish operator to the graph by searching for it in the palette and dragging onto the Composite
- Right-click on the SPSSPublish operator and select Edit to open the Properties view
-
Click on the Output Ports tab and add the following Output stream schema:
Name: fileName Type: rstringNote: You can use the above to copy and paste into the Studio parameters page. When finished the values should match the ones below.
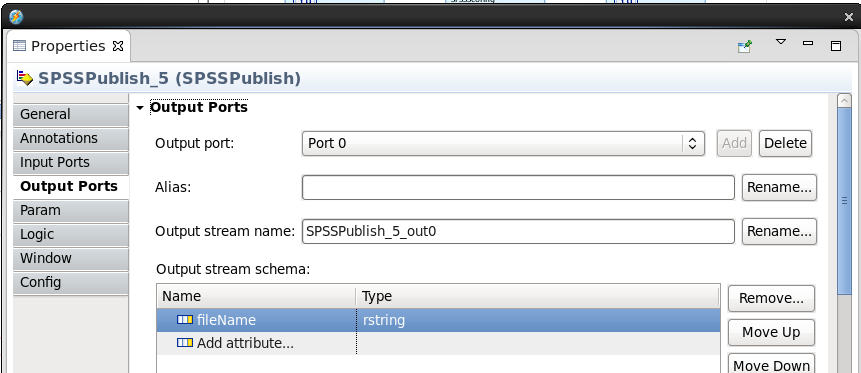
-
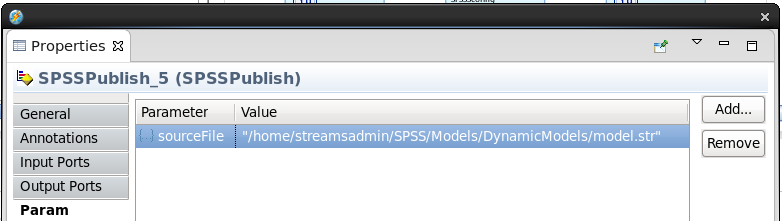
Click on the Param tab and add the following parameter (you will need to update the path to reflect the location where you extracted the SPSSModels.zip file):
sourceFile: "/home/streamsadmin/SPSS/Models/DynamicModels/model.str"Note: You can use the above to copy and paste into the Studio parameters page. When finished, the values should match the ones below.
- In the graph, right-click on the SPSSScoring operator (called scorer) and select Edit to open the Properties view for the operator.
- Click on the “Input Ports” tab and then click Add to add a new input port to the operator.
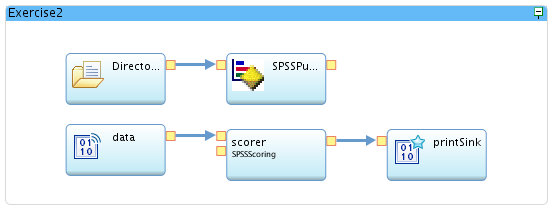
-
Now, drag a stream from the output port of the DirectoryScan operator to the input port of the SPSSPublish operator. The graph should now look like this:
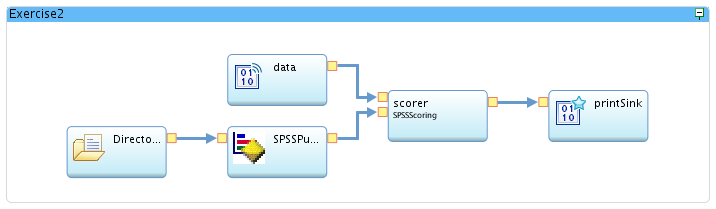
-
Finally, drag a stream from the output of the SPSSPublish operator to the new input port of the SPSSScoring (scorer) operator. The final graph should look like this:
- Save the changes and fix any errors identified in the compile.
Launch
Launch the distributed build. The first run will produce the following output. Notice that the actualClass and the predictioN values do not match. This is because we are still using the default function (RBF) that does not correctly predict this patient record.

Now copy the new polynomial based model to DynmicModels/model.str (this directory should already exist at the location where you extracted SPSSModels.zip). For example:
cp /home/streamsadmin/SPSS/Models/svm_cancer-betterpoly.str /home/streamsadmin/SPSS/Models/DynamicModels/model.str
The output in the console will begin to show the following:

Congratulations! You have now created applications with the SPSS toolkit!