API features: Scalability, fault tolerance
Edit meThis section will discuss how to scale your processing and about fault tolerance of your application.
- Scalability: Parallel region
- Fault tolerance: Consistent region
Parallel region
If a particular portion of your graph is causing congestion because the application needs additional throughput at that point, you can define a parallel region in your graph. A parallel region enables the application to use multiple channels to run transforms (such as filtering or modifying data) concurrently.
In a previous example, you created a topology and defined a pseudo temperature source. In this example, you want to convert all of the source tuples from Celsius to Kelvin.
To achieve this, add a function called convertToKelvin() to the application you created in an earlier section.
Your application is contained in two files.
The following code is in the ‘temperature_sensor.py’ file:
from streamsx.topology.topology import Topology
import streamsx.topology.context
import temperature_sensor_functions
import random
def readings():
while True:
yield random.gauss(0.0, 1.0)
def convertToKelvin(tuple) :
return tuple + 273.15
def main():
topo = Topology("temperature_sensor")
source = topo.source(temperature_sensor_functions.readings)
kelvin = source.map(temperature_sensor_functions.convertToKelvin)
kelvin.for_each(print)
streamsx.topology.context.submit("STANDALONE", topo)
if __name__ == '__main__':
main()
Converting a temperature reading from Celsius to Kelvin is not a resource-intensive task. However, you can use this example to see how using a parallel region can help distribute processing across resources when a transform is resource-intensive or inefficient and is causing a bottleneck in your application.
To parallelize a transform, invoke .parallel() on a Stream object where you want to process data in parallel.
To end parallel processing, invoke .end_parallel() on the parallelized Stream object. When you invoke end_parallel(), subsequent transforms on the Stream object that is returned by end_parallel() are not processed in parallel. For example, if you call .end_parallel() on the kelvin Stream object before you call for_each(print), the for_each(print) function is not processed in parallel.
The previous example is replaced with the following code:
def main():
topo = Topology("temperature_sensor")
source = topo.source(temperature_sensor_functions.readings)
kelvin = source.parallel(4).map(temperature_sensor_functions.convertToKelvin)
end = kelvin.end_parallel()
end.for_each(print)
streamsx.topology.context.submit("STANDALONE", topo)
Any transforms that are performed on the parallelized Stream object occur in parallel to the degree that is specified in the .parallel() function. In this example, you specified 4, which means that four channels process the data in the parallel region on the graph.
Consistent region
Because of business requirements, some applications require that all tuples in an application are processed at least once. By default any state is reset to its initial state after a processing element (PE) restart. A restart may occur due to:
- a failure in the PE or its resource,
- a explicit PE restart request,
You can use a consistent region in your stream processing applications to avoid data loss due to software or hardware failure and meet your requirements for at-least-once processing.
The application or a portion of it may be configured to maintain state after a PE restart by the mechanism consistent region. A consistent region is a subgraph where the states of callables become consistent by processing all the tuples at least once within defined points on a stream. On a failure, a region is reset to its last successfully persisted state, and source callable of a region can replay any tuples submitted after the restored state.
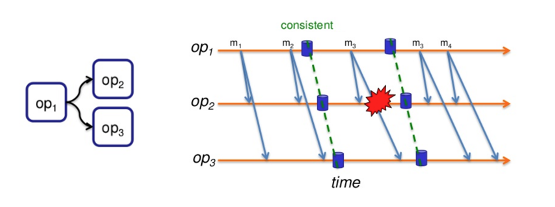
The consistent region feature requires a configured checkpoint repository in the Streams instance and Streams applications must be submitted in DISTRIBUTED context.
This section will discuss how to create stream processing applications with the consistent region feature:
Configure a consistent region
The recommended way to create a ConsistentRegionConfig is to call either operator_driven() or periodic().
Note: operator_driven() cannot be used when a Python callable is the begin of the consistent region (CR) as there is no Python API to trigger the region as we have for C++ or Java SPL operators. When SPL operators (Java or C++) are the start of a CR, the operator dictates when the region is made consistent, i.e. drained and checkpointed. Often additional operator parameters are required to control when the operator is supposed to trigger the region becoming consistent.
For example, set a source stream s to be a the start of an operator driven consistent region with a drain timeout of 60 seconds and a reset timeout of 90 seconds:
s.set_consistent(ConsistentRegionConfig.operatorDriven(drain_timeout=60, reset_timeout=90))
Example of a periodic consistent region configuration, IBM Streams runtime will trigger a drain and checkpoint every 30 seconds:
s.set_consistent(ConsistentRegionConfig.periodic(period=30, drain_timeout=120, reset_timeout=120, max_consecutive_attempts=6))
Reference
Stateful callables
Use of a class instance allows a transformation to be stateful by maintaining state in instance attributes across invocations.
When the callable is in a consistent region it is serialized using dill.
- The default serialization may be modified by using the standard Python pickle mechanism of
__getstate__and__setstate__. - If the callable has
__enter__and__exit__context manager methods then__enter__is called after the object has been deserialized by dill.
In the following sample application the class TimeCounter is invoked as source and configured as start of a consistent region.
The class VerifyNumericOrder is a sink and the end of the region.
The sample class TimeCounter implements __getstate__ and __enter__ in order to prevent that the metrics values are restored when state is recovered in the sample.
The following code is in the ‘cr-sample.py’ file:
from streamsx.topology.topology import Topology
import streamsx.topology.context
from streamsx.topology.state import ConsistentRegionConfig
from streamsx.topology.context import ConfigParams
import streamsx.spl.op as op
import streamsx.ec as ec
import itertools
import time
# Class defining a source of integers from 0 to the limit, including 0 but
# excluding the limit.
# An instance of this class can be dilled.
class TimeCounter(object):
"""Count up from zero every `period` seconds for a given number of
iterations."""
def __init__(self, period=None, iterations=None):
if period is None:
period = 1.0
self.period = period
self.iterations = iterations
self.count = 0
def __iter__(self):
return self
def _done(self):
return self.iterations is not None and self.count >= self.iterations
def __next__(self):
# If the number of iterations has been met, stop iterating.
if self._done():
self._metric2.value = 1
raise StopIteration
# Otherwise increment, sleep, and return.
to_return = self.count
self.count += 1
self._metric.value = self.count
time.sleep(self.period)
return to_return
def next(self):
return self.__next__()
def __enter__(self):
self._metric = ec.CustomMetric(self, "nTuplesSent", "Logical tuples sent")
self._metric.value = self.count
self._metric2 = ec.CustomMetric(self, "stopped", "Stop iterations")
self._metric2.value = int(self._done())
def __exit__(self, exc_type, exc_value, traceback):
pass
def __getstate__(self):
state = self.__dict__.copy()
if '_metric' in state:
del state['_metric']
if '_metric2' in state:
del state['_metric2']
return state
# Verify that tuples are received in strict numeric order.
class VerifyNumericOrder(object):
def __init__(self):
self._expected = 0
def __call__(self, x):
if x == self._expected:
self._expected += 1
else:
raise ValueError("Expected " + str(self._expected) + " got " + x)
def main():
topo = Topology("StatefulSample")
iterations = 3000
topo = Topology()
# Generate integers from [0,3000)
s = topo.source(TimeCounter(iterations=iterations, period=0.1))
# Configure source as start of consistent region, trigger periodically every 5 seconds
s.set_consistent(ConsistentRegionConfig.periodic(5))
# Verify that tuples are received in strict numeric order.
s.for_each(VerifyNumericOrder())
streamsx.topology.context.submit("DISTRIBUTED", topo)
if __name__ == '__main__':
main()
Use SPL operators supporting consistent region
It is recommended to have a complete consistent region from Source (start of a region) to Sink (end of a region) callables (SPL operators).
A proved SPL operator acting as start of a consistent region is streamsx.kafka.KafkaConsumer.
Find below a list of packages, that integrate SPL operators supporting consistent region:
References