Module 12 - Export streams
Edit meObjectives
In this module, you extend the ITE application that you created in the modules 1-8.
At the end of this module, your application export streams, which can be imported by another application.
After completing this module, you should be able to:
- Configure the export streams of the ITE application
- Connect another application to the exported streams of the ITE application
Prerequisites
You finished at least module 8 of the tutorial, in which you added the record deduplication.
Concepts
Imagine, you have the project requirement to plug in another application to the ITE application to apply new business rules. The performance of the external application must not affect the performance of the ITE application. If the importing application is too slow, then the ITE application drops the connection at export. You must accept, that your application cannot import tuples till the reconnection and data might be lost.
Customization Points
The following figure and table show the points that you need to customize in the ITE application during this module or that influence the customization like the different formats and stream schemes. Other parts don’t need to be customized because it is not necessary for this module.
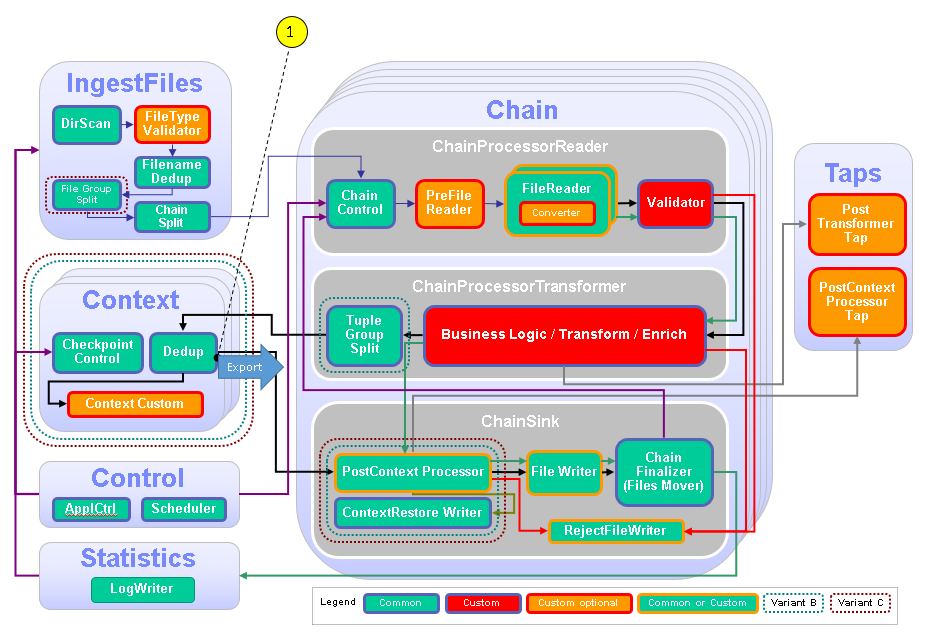
| Number | Functional Block | What needs to be customized? |
|---|---|---|
| 1 | Dedup | Configure the context output stream to be exported. |
Configuration
You do all configuration settings in the same manner as you did it in the previous modules. Expand teda.demoapp/Resources/config in the Streams Studio’s Project Explorer and open the config.cfg file. In all later steps, this opened file is referenced when config.cfg is mentioned.
Tasks
The configuration and customization consists of the following tasks:
- Configure the export streams
- Build the application to import the tuples from ITE application
Configure the export streams
You specify the export streams dedup to select the output stream of the BloomFilter operator to be exported in each group. The export operator provides the demoapp.streams::TypesCommon.TransformerOutType streams schema. You configure the export stream in the config.cfg file of the teda.demoapp project:
ite.export.streams=dedup
The ITE application framework creates an exporter with ite=”demoapp.context_output_Dedup” property and the dropConnection congestion policy to prevent back-pressure of the slow importer application.
You use the property to create an application that imports the output of ITE application.
This code is an example of the generated code in the ITE application framework:
() as Exporter = Export(OutDedupedStream) {
param
properties: { ite="demoapp.context_output_Dedup" };
allowFilter: true;
congestionPolicy: dropConnection; // prevents back-pressure from slow importer
}
You find the other supported ite.export.streams configuration settings in the IBM Knowledge Center under Reference>Toolkits>SPL standard and specialized toolkits>com.ibm.streams.teda 2.0.0> Parameter reference
Build the application to import the tuples from the ITE application
Your application that imports the tuples from the ITE application, it must subscribe the ite==”demoapp.context_output_Dedup” property. You must use the same streams schema specification as the ITE implementation. You obtain the streams schema with the inclusion of the use clause use demoapp.streams::*; in the spl code of your importer application.
The example of the Import operator shows the specified settings:
stream<TypesCommon.TransformerOutType> In = Import() {
param subscription : ite=="demoapp.context_output_Dedup";
}
You must download and use the teda.import sample project to understand the function of the plug-in interface.
- Download the teda.import.zip project package.
- Extract the downloaded file.
- Import the existing project to Streams Studio as an existing project. (File->Import..->General->Existing Projects into Workspace)
- Build the
teda.importproject.
The project includes a DemoappImportDedup.spl file. This file contains two main composites. The build configuration is prepared to start both importer applications.
The DemoappImportDedup main composite implements an easy sample that you typically use to import the tuples from the ITE application.
The DemoappImportDedupSlowmain composite blocks the tuple processing to provoke the back-pressure on the ITE application.
Building and starting the ITE application
After you restructure the project, it is best practice to clean the project before you start a new build process. To do so, select on the Streams Studio main menu Project > Clean… and select the teda.demoapp project. Press OK.
REMEMBER: You must clean the generated output from the ITE application before you start. You can remove the checkpoint and out directories from Streams Studio or command line:
cd WORKSPACE/teda.demoapp/data
rm -rv checkpoint out
If you restart the Lookup Manager application, then you must remove the control and out directories from Streams Studio or command line:
cd WORKSPACE/teda.lookupmgr/data
rm -rv control out
You need to do the same steps as in Module 7: Starting the applications to launch the applications and to process the input files.
Follow the same steps to load the lookup data and monitor the application’s status as in Module 7: Loading the lookup data
Note:
If your Lookup Manager is still running and the lookup data was loaded already before, then you can launch the ITE application and trigger the restart command in the control directory. In this case, the init command does not need to be processed again to synchronize the Lookup Manager and ITE applications.
Change into the <WORKSPACE>/teda.lookupmgr/data/control directory and create the appl.ctl.cmd file with content of the
wanted command, in this case: restart,demoapp.
cd <WORKSPACE>/teda.lookupmgr/data/control
echo 'restart,demoapp' > appl.ctl.cmd
ITE application and Lookup Manager application establish a control sequence where at the end both applications are in RUN state by using the data already available, without reload.
Starting the Importer applications and discussing the results
The importer application must connect the ITE application before you start the file processing. Your ITE application must process a huge volume of data to recognize the back-pressure.
You start with some preparation steps:
- Download the ITE input files Part1.zip and Part2.zip and expand them to your local file system.
- Ensure that the ITE and the Lookup Manager applications are healthy, running and in
RUNstate (‘green’ state in the Monitoring GUI) - Open the Instance Graph view from Streams Explorer view in Streams Studio
- Select Flow as the Color Schema for the graph to monitor the tuple processing.
Starting DemoappImportDedup application.
You can start the DemoappImportDedup application.
- Expand the teda.import project tree to
teda.import>teda.import>DemoappImportDedup[Build:BuildConfigFast]>BuildConfigFast[Active] - Launch the application as Distributed.
- Change the view to
Instance Graph. - Verify in the
Instance Graphthat the Importer application is connected to the ITE application
Process the ITE input data from the Part1 directory.
Move all included .csv files from Part1 folder to the WORKSPACE/teda.demoapp/data/in directory.
Discussing the tuple processing in the Instance Graph.
The ITE application and the Importer application process the same rate of tuples.
The Monitoring GUI provides all three EXPORT metrics for demoapp.context_output_Dedup (Context00), demoapp.context_output_Dedup (Context01)and demoapp.context_output_Dedup (Context02) connections.
The counter nConnections equals to 1 and the counter nBrokenConnections equals to 0. The importing application does not slow down the ITE application.
Cancel the DemoappImportDedup application, now.
The Monitoring GUI updates the nConnections counter to 0.
Starting DemoappImportDedupSlow application.
You must start the DemoappImportDedupSlow application, now.
- Expand the teda.import project tree to
teda.import>teda.import>DemoappImportDedupSlow[Build:BuildConfig]>BuildConfig[Active] - Launch the application as Distributed.
- Change the view to
Instance Graph. - Verify in the
Instance Graphthat the Importer application is connected to the ITE application
Process the ITE input data from the Part2 directory.
Move all included .csv files from Part2 folder to the WORKSPACE/teda.demoapp/data/in directory.
Discussing tuple processing in the Instance Graph.
The ITE application and the Importer application process tuples in different rates. The Importer application is slower than the ITE application. But you observe in the graph that the tuple rate of the ITE application is the same as during file processing that you started earlier. In this run and in the run before, the importing application does not slow down the ITE application.
The nBrokenConnections counter shows many broken connections in the Export metrics that the Monitoring GUI shows.
Next steps
This module covers the basics of writing applications with the Telecommunications Event Data Analytics (TEDA) application framework. To learn more about the details, refer to the IBM Knowledge Center.
We continue to improve this tutorial. If you have any feedback, please click the Feedback button at the top and let us know what you think!